Query String Reference
Cloud CMS lets you search for your content using either a text-based query string or a JSON block. These two methods are fairly equivalent for most typical operations. They provide two ways to express a search operation that will execute within ElasticSearch. They are expressions of the ElasticSearch DSL.
This portion of the documentation goes into some of the things you can do with the former, textual representation of an ElasticSearch query string. In Cloud CMS, you can type these strings in the Search box to pull back accurate results across you entire content base.
A full reference for query string support can be found on ElasticSearch's website:
https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-query-string-query.html
Case Insensitivity
All searches are case-insensitive. A search for Michael Jordan is the same as a search for michael jordan.
All content is indexed in lowercase and all queries are converted to lowercase before being executed.
Full Text Search
To begin, you're always able to simply search for text. A query string, if nothing else, provides some text that you want to find in the content store.
For example, if you wanted to find all the documents with the word cat in them, you can just type in:
cat
Cloud CMS will pull back all the content that has those three letters appearing in the JSON or in the binary attachments of the nodes. For example, the following node would be returned:
{
"title": "The cat ate my homework"
}
In addition, the following node would be a match (since the word cations has cat in it)
{
"title": "Foundations of Chemistry",
"description": "A study in anions and cations"
}
Finally, suppose you uploaded a PDF version of Gone with the Wind. This would also be a match. It's a match because the first paragraph of the first page contains cat:
"Scarlett O'Hara was not beautiful, but men seldom realized it when caught by her charm as the Tarleton twins were. In her face were too sharply blended the delicate features of her mother, a Coast aristocrat of French descent, and the heavy ones of her florid Irish father."
The match occurs in the word delicate.
In Cloud CMS, a full-text search is performed when no special characters are found within the search term. If you just type in some words, Cloud CMS will automatically perform a wildcard search using your search terms. This is similar to you can read about below in the section on Wildcards.
Exact Match
Suppose you wanted to find an exact match for the word cat. You can specify an exact match by using double quotes, like this:
"cat"
In this case, the following will match:
{
"title": "The cat ate my homework"
}
In addition, our Gone with the Wind PDF will match. However, it matches because the word cat appears all by itself on page 74:
"Don't be a cat, Miss," said her mother.
AND / OR / NOT
As you might expect, you can use AND and OR to join multiple terms together. For example:
cat AND dog
cat OR dog
You can also use the && and || operators instead of AND and OR, like this:
cat && dog
cat || dog
And you can use NOT or ! to indicate negation. For example:
cat AND NOT dog
cat && !dog
(cat AND dog) OR (fish AND NOT dog)
(cat && dog) || (fish && !dog)
(cat AND dog || (fish AND !dog)
And so on.
Include and Exclude Terms
You can use + and - to require that a term be included or excluded.
For example, to find nodes where the word cat appears but the word dog does not appear, you can do:
+cat -dog
The + operator indicates that a term must be present. The - operator indicates that a term must not be present.
Grouping
You can use parenthesis to further group terms. Such as:
(cat OR dog) AND fish
This will find any matches where fish must appear and either cat or dog must appear.
Specific Fields
At times, you may wish to constrain your search to specific fields. For example, suppose you wanted to find matches where the word cat appears in the title. You can write your query like this:
title:cat
And if you wanted an exact match against the title, you could do:
title:"cat"
You can also combine this with grouping and logical operators to do something like:
(title:cat AND category:veterinary) OR (title:dog AND category:veterinary)
Or:
(title:cat OR title:dog) AND category:veterinary
Or:
title:(cat OR dog) AND category:veterinary
You can specify sub-fields using dot-delimited notation.
Suppose we had a document like this:
{
"title": "Solon Animal Clinic",
"category": {
"label": "veterinary",
"weight": 3,
"vet": "Sylvester the Cat"
}
}
We can find all matches where the category.label field is veterinary like this:
category.label:veterinary
You can also use wildcards to specify sub-fields. Suppose you wanted to match any fields under category. You can do so like this:
category.\\*:veterinary
Or:
(category.\\*:veterinary OR category.\\*:medical) AND category.weight:3
Note the use of a double-backslash (\\). This is a required convention when using ElasticSearch.
Content ID
Every document indexed into ElasticSearch has a special _id field which stores the ID of the document.
_id:9603aa96874549758e15
Content Type
Every document indexed into ElasticSearch has a special __type field which stores the Cloud CMS content type QName. This is equivalent to the _type field in the JSON and for reasons that have to do with the internals of ElasticSearch, it is available as __type instead of _type.
At any rate, lets say you want to find all content instances that are books (of type my:book).
You can search for:
__type:"my:book"
If you wanted to search for books and articles, you can use an OR and do it like this:
__type:("my:book" OR "my:article")
Content QName
Every piece of content in Cloud CMS has a QName. The QName is available within searches as the _qname field.
_qname:"o:9603aa96874549758e15"
System Metadata
Content system metadata is indexed into ElasticSearch. This is available on the _system sub-object. You can use this information for field-level matching.
For example, you could find all books that exist on a changeset:
__type:"my:book" AND _system.changeset:"38:4041e14ca9e55ae4baa1"
For more information on system metadata, please read up on System Metadata.
Working with Dates
Every document that Cloud CMS stores into ElasticSearch has at least three dates stored for it:
_system.created_on
The creation date is the date when the node was created in Cloud CMS.
_system.modified_on
The modification date stores the date when the node was last modified (either by an editorial user or by a system process). It stores the last time the document was touched for any reason.
_system.edited_on
The editing date stores the last time an editorial user intentionally modified the document. This is often different from the modification date since it only reflects intentional editorial modifications.
The internal structure of these date objects looks like this:
{
"timestamp": "25-Sep-2018 22:27:54",
"year": 2018,
"month": 8,
"day_of_month": 25,
"hour": 22,
"minute": 27,
"second": 54,
"millisecond": 479,
"ms": 1537928874479,
"iso_8601": "2018-09-25T22:27:54-04:00"
}
These fields are available to use within your search queries as you see fit. For example, if you wanted to find all the documents that were modified in 2018, you could write:
_system.modified_on.year:2018
If you wanted to find all books that were modified in February of any year, you could write:
__type:"my:book" AND _system.modified_on.month:1
Note that months are 0-indexed. January is 0. February is 1 and so on. Yes, this is a bit odd, but once again, have you pondered the duck-billed platypus recently?
The ms portion of the object above stores the epoch millis. This is compatible with ElasticSearch's native date search capabilities.
As such, you can write range queries using this date field. Suppose you want to find content that was edited between January 1, 2015 and December 31, 2018. You can write:
_system.edited_on.ms:[2015-01-01 TO 2018-12-31]
Or if you just want to find anything written before December 31, 2017:
_system.created_on.ms:[* TO 2018-12-31]
Or maybe you want to find content that was created between 9:15am on Feb 5, 2018 and 5:32pm on Feb 7, 2018:
_system.edited_on.ms:[2018-02-05T09:15:00 TO 2018-02-07T17:32:00]
Content Features
Any features that have been applied to your content instances are available via the _features sub-object.
To pull back content that has the f:container feature, you can do:
_exists_:_features.f\\:container
Note that the dot-delimited field _features.f:container has to be escaped with a double-backslash. That's because of the way that ElasticSearch internally stores things. Yes, this is a bit odd, but once again, have you pondered the duck-billed platypus recently?
Exists
You can check for existence of a field using the _exists_ special field:
_exists_:title
_exists_:category.weight
Wildcards
You can use the * and ? characters to perform wildcard searches. Use * when you want to match an unspecified range of characters. Use ? when you want to match a single character.
For example, if you searched for *cat*, Cloud CMS will find documents that contain a wide array of words, including:
cat
catch
cation
vacation
tomcat
Any many more.
Similarly, if you searched for ?at, you would find documents that contained:
cat
bat
rat
fat
sat
mat
And many more. Note that this would only match 3-letter words. If you wanted to find longer words where these three-letter words were components within the larger words, you might search for *?at*.
Bear in mind that wildcard searches consume time and memory to execute. You should expect wildcard queries to exhibit degraded performance versus direct value queries.
Regular Expressions
If you're hardcore, you can use regular expressions to match search terms. For example, suppose you wanted to find any nodes where someone said Don't be a cat. You might search for:
^(.*)Don't be a cat(.*)said(.*)$
This will match nodes that have the following text:
"Don't be a cat, Miss," said her mother.
"I said don't be a cat this time," said Joe.
"Really, don't be a cat, not that kind at least," said Bill.
Remember that in Cloud CMS, all textual searches are case-insensitive.
You can leverage the full power of regular expressions to perform some pretty accurate lookups. We recommend taking a look at the [https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-regexp-query.html#regexp-syntax] (ElasticSearch Query DSL Regular Expression Guide).
We also recommend using an online regular expression tester, such as https://regex101.com.
Fuzziness
Use the ~ character to indicate a fuzzy search around a term. A fuzzy search will match on terms that are exact and also similar to the prescribed term.
For example, you might search for:
Scarlett~
By default, this will find exact matches for the term Scarlett but will also find matches for variations of this term where 2 edits have been made. As such, the following will all match:
Scarlett
carlett
Scarlet
Sarlett
Sarlet
This can be very useful for matching on text entries where there may be typos or misspellings.
You can also control the number of edits in the fuzzy search. For example, if you wanted to match for a misspelling like Sarclet, you will need 3 edits:
- There is a missing
cafter the firstS. - There is an errant additional
cafter ther. - There is a missing
tat the end
You can adjust the search to account for 3 edits like this:
Scarlett~3
Proximity
If you wrap a text search in double-quotes (i.e. "), it will be searched as an exact phrase match. This implies that the words in the phrase are to be ordered exactly as stated. However, there are times where you might want the words in the phrase to be spaced out from one another. They may exist with other words between them and so on. This is known as proximity.
For example, suppose we have the following sentences:
The Milwaukee Brewers are going to win the World Series
The Brewers should win the World Series
Bob Uecker things the Brewers will win the World Series
Anyone else think the Brewers could win the 2018 World Series?
If we did an exact phrase match for "Brewers win World Series", we'd get 0 matches since that literal phrase does not exist in any of these.
We can use proximity to describe a maximum edit distance between words. An edit distance in this case is the number of words between the words in our search phrase that we will allow.
We could search for:
"Brewers win World Series"~5
Within the Cloud CMS UI, you can run this search and see the scoring come back:
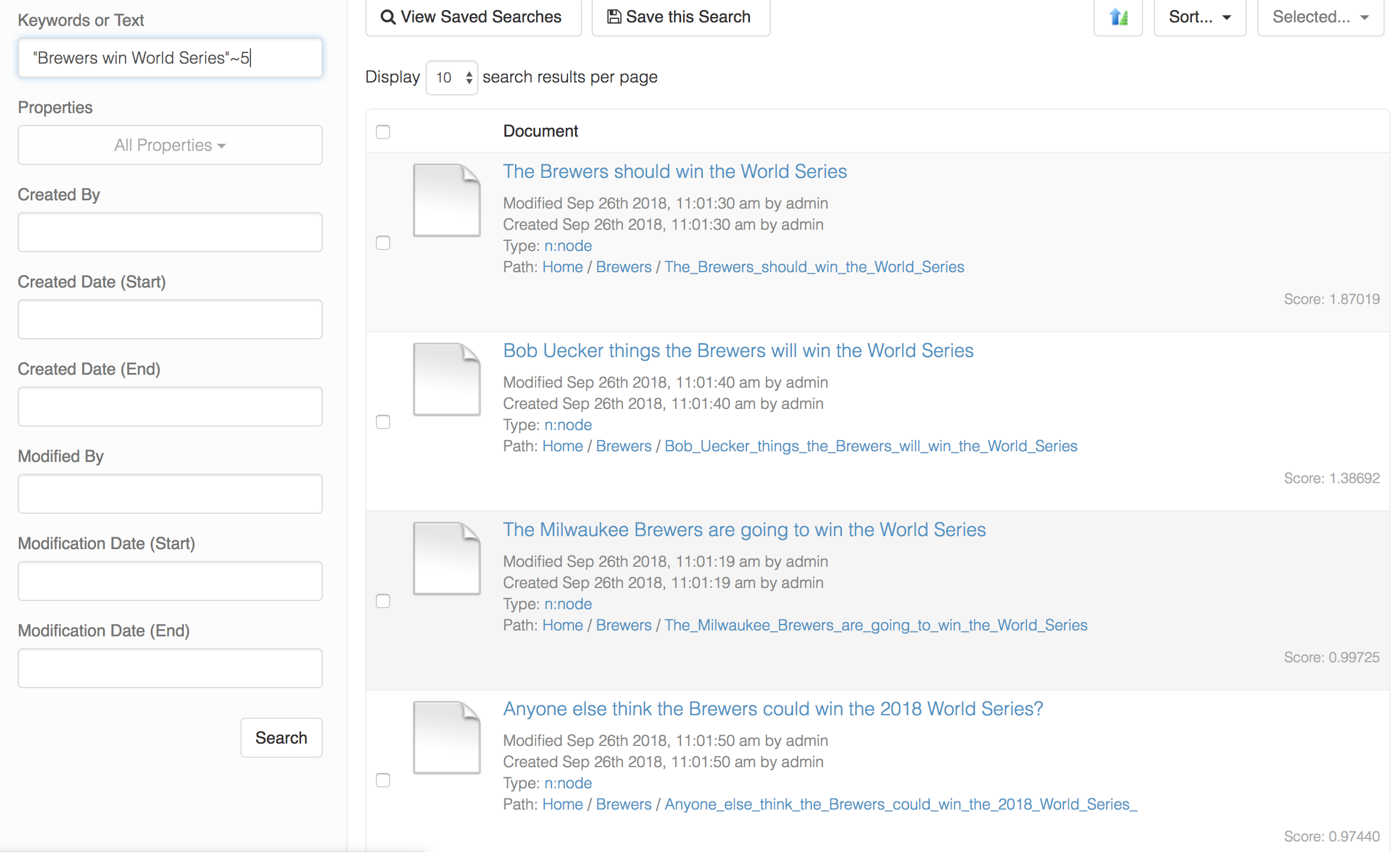
The results along with their scores are:
- The Brewers should win the World Series (1.87019)
- Bob Uecker things the Brewers will win the World Series (1.38692)
- The Milwaukee Brewers are going to win the World Series (0.99725)
- Anyone else think the Brewers could win the 2018 World Series? (0.97440)
The first result gets the highest score because the proximity factor is 2 which is pretty low. This means that only 2 words had to be inserted to complete the match (those words are should and the).
The last result scores the lowest because it has a higher proximity factor 3 (could, the, 2018) and also has a partial match on Series? (with the added question mark).
Value Ranges
You can use ElasticSearch to search against fields than span a range in value. For example, you might search for content where a price falls within a certain range or a date falls within a certain range.
The [ and ] characters are used to describe upper and lower limits that are inclusive of those limits. The { and } characters are used to describe upper and lower limits that are NOT inclusive of those limits.
Thus -
- If you were to say
[0 TO 5], this would mean0, 1,2,3,4and5`. - If you were to say
{0 TO 5}, this would mean1,2,3, and4. - If you were to say
{0 TO 5], this would mean1,2,3,4and5.
Suppose you have a collection of books of type my:book with ratings and years. They may look like this:
[{
"title": "The Philosopher's Stone",
"rating": 8.0,
"year": 1997
}, {
"title": "The Chamber of Secrets",
"rating": 8.2,
"year": 1998
}, {
"title": "The Prisoner of Azkaban",
"rating": 9.1,
"year": 1999
}, {
"title": "The Goblet of Fire",
"rating": 8.8,
"year": 2000
}, {
"title": "The Order of the Phoenix",
"rating": 7.8,
"year": 2003
}, {
"title": "The Half-Blood Prince",
"rating": 8.4,
"year": 2005
}, {
"title": "The Deathly Hallows",
"rating": 8.7,
"year": 2007
}]
Not all may agree with this list but let's go with it. You could do the following:
- Find all books with a rating between 8 and 9
rating:[8 TO 9]
- Find all books with a rating greater than 8 (but not including 8 itself):
rating:{8 TO *]
- Find all books rated higher than 8.5 which came out only for 2001 and beyond:
__type:"my:book" AND rating:[8.5 TO *] AND year:{2000 TO *]
You can also use the <, >, <= and >= symbols to achieve the same thing.
rating:(>=8 AND <=9)
rating:(>8)
__type:"my:book" AND rating:(>=8.5) AND year:(>2000)
Boosting
By default, Cloud CMS does not assign weights to search terms when they are indexed. This means that matching terms essentially have equal weight. Suppose we were to search for:
cat OR dog
The computer search scores would be equivalent no matter whether the match was for cat or for dog. What if wanted to give preference to one term over the other such that matches for dog might be more important than matches for cat?
We can boost the search score for matches on dog by using the ^ operator.
Suppose we want matches for dog to get twice the scoring as those for cat. We could do:
cat OR dog^2
We can also use this for phrases:
"Scarlett O'Hara"^3
You can use boosts across fields:
__type:"my:book"^2 AND status:(live OR archived)^3