GraphQL
Cloud CMS supports query via GraphQL. GraphQL is offered as a core API that sits alongside the Cloud CMS REST APIs.
GraphQL is an open-source data query and manipulation language specification that is widely used across many CMS systems, servers and clients. GraphQL is offered to make it even easier for developers to quickly integrate and work with content inside of Cloud CMS.
In Cloud CMS, all GraphQL calls are scoped to a branch. Each branch has its own GraphQL SDL schema that is maintained and recompiled on the fly as your content model changes on that branch. The properties defined on your content model will be available as properties in your GraphQL schema.
In addition, Cloud CMS automatically makes available collection properties for all of your content types. These collections can be queried using the MongoDB query, ElasticSearch DSL and pagination (sort, limit, skip).
Our philosophy in offering GraphQL is to provide developers with a full implementation that rides on top of the best that Cloud CMS has to offer in terms of query and search. As such, we let developers fully define custom queries and search operations at any level in the query call.
At Cloud CMS, we're big fans of GraphQL. Our view of GraphQL is that provides a really nice way to describe a "shape" of content that you wish to retrieve. The "shape" description is passed into GraphQL and Cloud CMS retrieves all the data needed on the server side. It can then hand it back in one fell swoop. This reduces API calls and lets developers grab at everything they need in one go.
User Interface / Development
Cloud CMS offers a tool within its user interface that gives GraphQL developers an easy way to inspect the GraphQL SDL schema for a branch and test their custom queries. This tool is available under Manage Project > GraphQL.
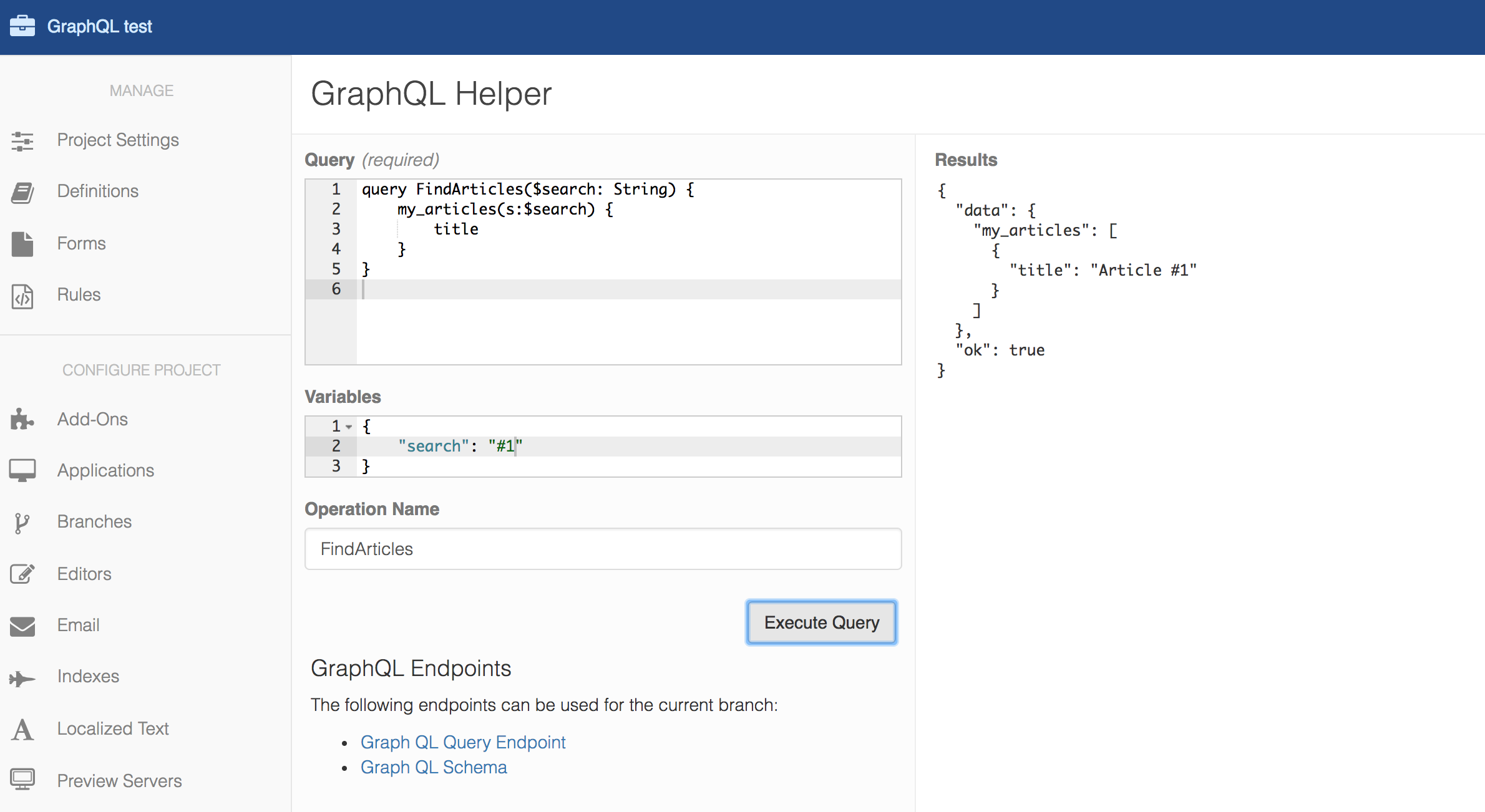
Branch-scoped Query
All GraphQL calls are scoped to a branch. Every branch may have a unique content model (different content types, relationships, etc.) and so the GraphQL schema for each branch is auto-generated on the fly.
You can execute GraphQL queries using a POST:
POST /repositories/{repositoryId}/branches/{branchId}/graphql
Or a GET:
GET /repositories/{repositoryId}/branches/{branchId}/graphql?query=<querystring>
POST
When using an HTTP POST, you have two options:
- You can POST a JSON payload with Content-Type
application/json. In this case, the payload should look like this:
{
"query": "<GraphQL query string>"
}
Cloud CMS supports the optional variables and operationName properties as well. If you want to specify those, you can do so in a way similar to this:
{
"query": "<GraphQL query string>",
"variables": {
"property1": "value1",
"property2": 10
},
"operationName": "FindArticles"
}
- Or you can POST a GraphQL query string (text) with Content-Type
application/graphql. In this case, the payload should simply be a text string containing the GraphQL query.
The following two calls achieve the same thing:
POST /repositories/{repositoryId}/branches/{branchId}/graphql
{
"query": "query {\nstore_books {\ntitle\nsummary\n}\n}"
}
And:
POST /repositories/{repositoryId}/branches/{branchId}/graphql
query {\nstore_books {\ntitle\nsummary\n}\n}
The optional variables and operationName can be passed in using request parameters.
GET
When using an HTTP GET, you should simply pass the query string as a request parameter.
For example, suppose you want to search for store:book instances and hand back a few properties for each. The query might look like:
query {
store_books {
title
summary
}
}
Here is the same query from before (executed using an HTTP GET):
GET /repositories/{repositoryId}/branches/{branchId}/graphql?query=%7B%5Cnstore_books%20%7B%5Cntitle%5Cnsummary%5Cn%7D%5Cn%7D
The optional variables and operationName can be passed in using request parameters.
Schema
Each GraphQL call runs against a schema that includes all the content types in your branch. To see this schema:
GET /repositories/{repositoryId}/branches/{branchId}/graphql/schema
GraphQL considers : to be a special character. As such, all type and property names have the : character replaced with _.
Here is a very simple example of a schema that includes a custom book content type named store:book.
schema {
query: QueryType
}
type store_book {
title: String
summary: String
rating: Int
}
type QueryType {
store_books(_doc: String, p: String, q: String, s: String): [store_book]!
}
Note that a store:book has three properties (title, summary and rating). The schema also exposes a root-level collection property named store_books that you can use to query, search and paginate across all books in the branch.
Collections
When querying against types, the following arguments are always supported:
_doc- the exact ID (_doc) of the document you'd like to retrieve
Or:
q- a string containing the JSON for a query operations- a string containing the JSON for a search operationp- a string containing the JSON for a pagination objectpath- a path string, containing all returned results to those which are contained within this filefolder treedepth- optional depth integer string restricting how deep to search folders (only valid when apathis configured)
If doc is specified, then a result set is produced with 1 match in it. Otherwise, the query, search and pagination parameters are used to produce a list.
If you're querying against a relator property, only the IDs of related items will be operated against.
Query
Using the example above, we can use GraphQL to find all books where rating is greater than 3:
query {
store_books(q:"{rating: { $gt: 3}}") {
title
summary
}
}
The value passed into q is a Cloud CMS query that uses the MongoDB query syntax.
Search
Suppose we want to search for all books that contain the word Scarlett in them. We can write:
query {
store_books(s:"Scarlett") {
title
summary
}
}
We can also use the ElasticSearch query string syntax to make our search more complex.
Suppose want to find all books that contain the word Scarlett but we want to allow for a fuzziness factor of 2 (allowing for 2 typos). We may also want to exclude any matches that contain the word Rhett in the title.
query {
store_books(s:"Scarlett~2 -title:Rhett") {
title
summary
}
}
We may also prefer to use the ElasticSearch DSL directly, like this:
query {
store_books(s:"{ query: { query_string: { query: 'Scarlett~2 -title:Rhett' } } }") {
title
summary
}
}
Pagination
We can use the p option to paginate. Suppose want to skip ahead 10 items in the record set and only hand back the first 20 items. And maybe we want to sort the results on title descending.
query {
store_books(p:"{ skip: 10, limit: 20, sort: { title: -1 } }") {
title
summary
}
}
Path Lookup
We can use the path option to restrict query results to only nodes that are contained within a certain folder, and optionally configure a depth to search. Suppose we want to lookup books contained in the "Romance" folder, searching to a maximum depth of 2 within this tree. The query might look something like this:
query {
store_books(path: "/Romance", depth: "2") {
title
summary
}
}
Everything at Once
Like Prince said, let's go crazy.
Let's find all the books with a rating greater than 3 that contain the word Scarlett (allowing for some typos) but that don't contain the word Rhett and let's also skip ahead 10 and get back the first 20 while sorting by title descending:
query {
store_books(q:"{rating: { $gt: 3}}" s:"Scarlett~2 -title:Rhett" p:"{ skip: 10, limit: 20, sort: { title: -1 } }") {
title
summary
}
}
The point is that you can use query, search and pagination all at the same time. For those who are hip in all things Cloud CMS, you'll recognize this as a Find Operation. We've made this ability available to GraphQL queries via the mechanism above.
Relator Properties
The Cloud CMS GraphQL implementation automatically creates collection properties for types that have relator properties.
Suppose the store:book type had an author relator property that pointed to a single node of type store:author. It might also have a reviews relator property that points to zero or more nodes of type store:review.
The schema might look like this:
schema {
query: QueryType
}
type store_book {
title: String
summary: String
author: store_author
reviews(_doc: String, _doc: String, p: String, q: String, s: String): [store_review]!
}
type store_author {
title: String
firstName: String
lastName: String
}
type store_review {
title: String
summary: String
rating: Int
}
type QueryType {
store_books(_doc: String, p: String, q: String, s: String): [store_book]!
}
We use relator properties within GraphQL to build out nested queries. The goal is to pull back content in one fell swoop.
Let's find all books where the word Scarlett appears (allowing for 2 typos) where the word Rhett doesn't appear in the title:
query {
store_books(s:"Scarlett~2 -title:Rhett") {
title
summary
}
}
This would just hand back books. It wouldn't hand back anything about the author or the reviews. We can grab the author and all the reviews like this:
query {
store_books(s:"Scarlett~2 -title:Rhett") {
title
summary
author
reviews
}
}
Let's say we only want to get back reviews where the rating is greater than 4 and the word awesome is contained somewhere within the review:
query {
store_books(s:"awesome") {
title
summary
author
reviews(q:"{rating: { $gt: 4}}")
}
}
You get the idea. You can nest queries within queries and so on down the shape of the content that you wish to retrieve.
It is important to keep in mind an important difference between the response from GraphQL and the response from the rest of the Cloud CMS REST API methods.
GraphQL responses will cater to the query passed in by the developer. The content you get back will change depending on what is requested and the content will also span multiple nodes. In effect, the content that comes back is a mapping of lots of nodes into one JSON response.
Whereas the Cloud CMS REST API generally paginates and returns record sets that contain nodes. Those nodes hand back 100% of the properties (unless you filter to hide properties).
Thus, from a CRUD perspective, the Cloud CMS REST API methods are superior. However, from a runtime retrieval perspective, developers will find a lot to enjoy about GraphQL.
Variables and Operation Name
In many of the cases shown above, you may prefer to split out your variables and use the GraphQL "variables" feature so that you can reuse your query block. Cloud CMS supports the optional GraphQL variables and operationName features.
Suppose you have the following query:
query {
my_articles(s:"Scarlett~2 -title:Rhett") {
title
summary
author
}
}
You can make the search term optional by writing the query like this:
query FindArticles($search: String) {
my_articles(s:$search) {
title
body
}
}
This is the same as the previous query except it has an operation name (FindArticles) and the operation takes a variable named $search. The $search variable is used in the query to populate the ElasticSearch query string.
We can invoke this query using the Cloud CMS API. Suppose wanted to search for Scarlett~2 -title:Rhett. We would simply pass a variables JSON block (using a request parameter or a within the JSON payload) that contains the search query string. We'd also pass an operationName to indicate the name of the named query operation we want to execute:
{
"variables": {
"search": "Scarlett~2 -title:Rhett"
},
"operationName": "FindArticles"
}
This is very useful for complex queries which may be written once and reused across many invocations with different variables on each call.
System Metadata
The generated GraphQL schema for any custom types will automatically include a custom _system subobject that provides system metadata. This _system subobject may appear something like what is shown here:
{
...,
"_system": {
"deleted": false,
"changeset": "40:84e03c7bbb4813a2e16e",
"created_on": {
"timestamp": "04-May-2016 10:08:20",
"year": 2016,
"month": 4,
"day_of_month": 4,
"hour": 10,
"minute": 8,
"second": 20,
"millisecond": 821,
"ms": 1462370900821
},
"created_by": "joesmith",
"created_by_principal_id": "cc4c84b0d0de2849de4b",
"created_by_principal_domain_id": "default",
"modified_on": {
"timestamp": "04-May-2016 10:08:20",
"year": 2016,
"month": 4,
"day_of_month": 4,
"hour": 10,
"minute": 8,
"second": 20,
"millisecond": 853,
"ms": 1462370900853
},
"modified_by": "admin",
"modified_by_principal_id": "cc4c84b0d0de2849de4b",
"modified_by_principal_domain_id": "default"
}
}
You can use the _system block to pull back any system-tracked metadata, including who created a piece of content, when it was last modified and the version of the content.
Here is a query that pulls back the modified_on system-tracked attribute:
query {
my_things {
title
_system {
modified_on {
timestamp
}
}
}
}
You can also use the _system block within your queries. Here is a query that hands back things that were modified in 2019.
query {
my_things(q:"{'_system.modified_on.year':%YEAR%}") {
title
}
}
Attachments
The generated GraphQL schema for any custom types will automatically include a _attachments subarray if the node being returned has any attachments on it.
{
...other properties...,
"_attachments": [{
"id": "attachmentId",
"type": "{content mimetype}",
"length": {content length in bytes},
"filename": "{optional file name}"
}]
}
Here is a query that pulls back attachments information for any matching nodes:
query {
my_things {
title
_attachments {
id
type
length
filename
}
}
}
You can also query for content that has a given attachment. To do so, you will need to use _system.attachments in your query. This is an object whose keys are the attachment ID and whose entries look like this:
{
"length": {content length in bytes},
"contentType": "{content mimetype}",
"filename": "{optional filename}"
}
Thus, you can do things like find content that has a default attachment of type image/jepg whose size is larger than 1K (or 1024 bytes).
query {
my_things(q:"{'_system.attachments.default.contentType':'image/jpeg','_system.attachments.default.length':{'$gt': 1024}}") {
title
}
}
Features
At the moment, limited feature information is supported for each node. However, you can currently test to see whether a node has a given feature, like this:
query {
my_things {
title
_features {
f_filename {
present
}
}
}
}
This tests to indicate whether the returned node has the f:filename feature. If it does, present will be true.
Paths
GraphQL can include file folder path metadata in the query results, using the _paths key:
query {
my_things {
title
_paths {
path
}
}
}
Paths will be returned in an array, with entries corresponding to each indexed root node.
Examples
We've collected some more examples here that may prove useful in terms of understanding how GraphQL works within Cloud CMS.
Find All Albums
Suppose you have a content type called my:album that looks like this:
{
"_qname": "my:article",
"type": "object",
"properties": {
"title": {
"type": "string"
},
"rating": {
"type": "number"
}
}
}
Using GraphQL, the following query will bring back all articles:
{
query {
my_albums {
title
rating
}
}
}
And the result might look like this:
{
"data": {
"my_albums": [{
"title": "The Endless River",
"rating": 4
}, {
"title": "The Division Bell",
"rating": 4.5
}, {
"title": "Momentary Lapse of Reason",
"rating": 3.75
}]
}
}
Query/Search and Paginate Albums
Suppose we now want to:
- Find all albums where the rating is greater than or equal to 4
- Within those albums, keep only the ones where the word
divisionappears - Paginate that result set (skip 0, limit 1)
We can do this within GraphQL by using the q, s and p arguments:
The query should be a MongoDB query. It might look like:
{
"rating": {
"$gte": 4
}
}
The search can either be an ElasticSearch DSL search object or simply a string of text. In this case, we'll pass in division as text.
Finally, for pagination, we can send an object like this:
{
"skip": 0,
"limit": 1,
"sort": {
"title": -1
}
}
This sets the skip and limit but also sets a sort for the retrieval. This sorts on title descending.
Putting it all together, the GraphQL query looks like this:
{
query {
my_albums(q:"{'rating:{$gte:4}'}, s:"division", p:"{skip:0, limit:1, sort: {title: -1}}") {
title
rating
}
}
}
And the result comes back:
{
"data": {
"my_albums": [{
"title": "The Division Bell",
"rating": 4.5
}]
}
}
Retrieving Paths
Suppose we wanted to retrieve the paths for our albums using a query.
We can run something like the following:
{
query {
my_albums {
title
_paths {
path
}
}
}
}
And we would get back something like:
{
"data": {
"my_albums": [{
"title": "The Division Bell",
"rating": 4.5,
"_paths": [{
"path": "/Artists/Pink Floyd/Albums"
}]
}, {
"title": "Doolittle",
"rating": 4.8,
"_paths": [{
"path": "/Artists/Pixies/Albums"
}]
}, {
"title": "Sailing to Philadelphia",
"rating": 4.2,
"_paths": [{
"path": "/Artists/Mark Knopfler/Albums"
}]
}]
}
}