API
The Cloud CMS API consists of an HTTP/HTTPS endpoint that uses OAuth 2.0 authentication. It supports both REST concepts and asynchronous data operations. You can access this API using any of our drivers as well as curl or any HTTP client library.
Our API provides functionality that covers all aspects of content production, publishing and presentation. 100% of the functionality of Cloud CMS is accessible from the API, including:
- Content Models, Creation and Editing
- Workflow, Scheduled Publishing and Release Management
- Users and Groups Management
- Role-based Authorities and ACL Security
- Binary Files and Attachments
- Versioning, Branching with Fork and Merge
- Query, Search, Traversal and Find Operations
- Replication and Content Transfer
- Data Warehouses and Analytics Capture
And much more.
The goal of this guide is to provide deeper information into the API, its object types and data stores that go beyond what is available in the developer Getting Started section and the API Explorer.
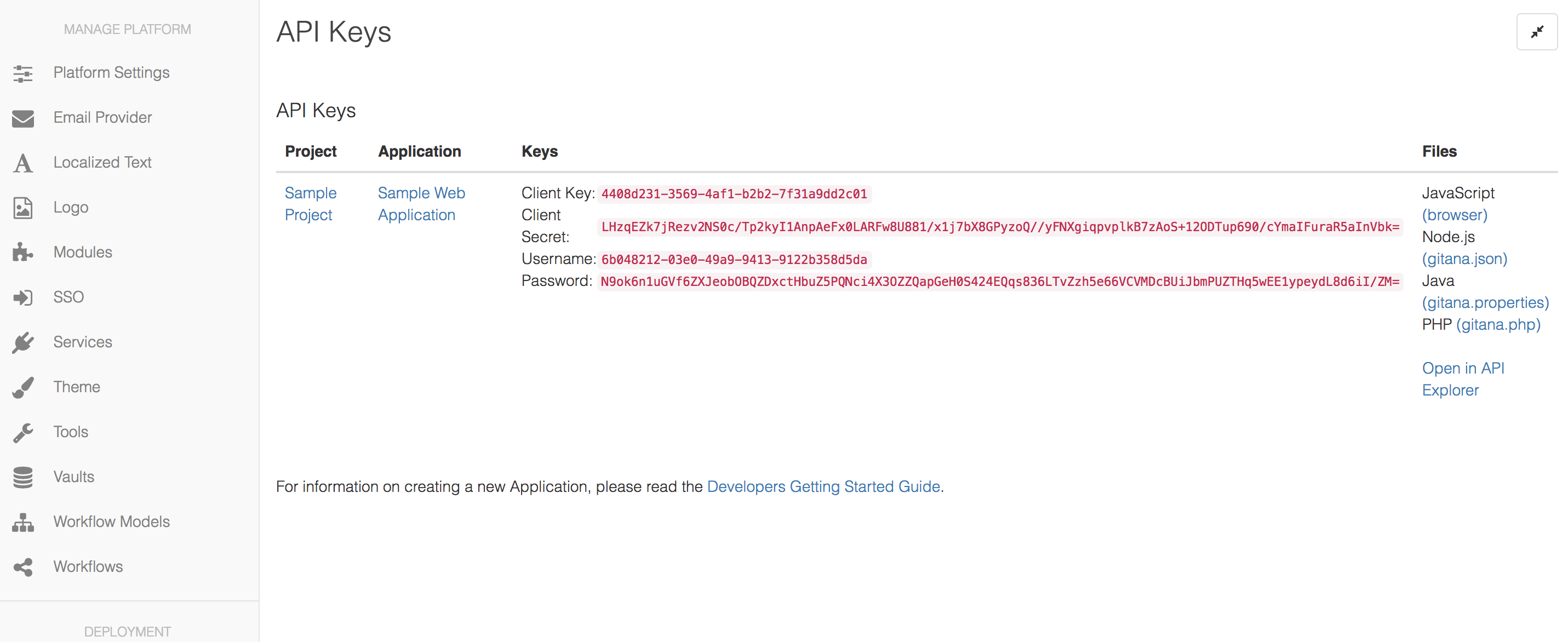
API Keys
Each Cloud CMS tenant may create as many API Key sets as they wish. To generate API keys, navigate into a Project and then create an Application. Each Application comes with its own set of API Keys.
You can view API Keys for a Project or for your entire Platform (across all Projects) by using the API Keys page on the left-hand navigation.
Your API keys appear along with links to download driver files:
For information on API Keys, please visit API Keys
Authentication
Cloud CMS has an HTTPS API that uses OAuth 2.0 for user assertion. Every request into Cloud CMS requires a OAuth 2.0 access token (a bearer token). There are no anonymous requests - user identity is asserted and access rights are checked for all services and objects accessed with every call.
For information on OAuth 2.0 authentication within Cloud CMS, please see our documentation on Authentication.
Endpoints
Cloud CMS is provided as a SaaS offering that is available at the following endpoint:
https://api.cloudcms.com
All requests are served over HTTPS.
On-premise installations can have any endpoint that they prefer. On-premise customers are required to manage their own DNS, routes and SSL certificates.
Formats
Cloud CMS supports JSON and binary attachment storage (Word, PDF, audio, video, etc.). Binary files that are uploaded are interrogated and extracted from. JSON is the primary storage format and the primary format for API requests and responses.
Rate Limiting
Cloud CMS SaaS tenants are configured for rate limiting. This limits the number of concurrent requests that may be executed against the Cloud CMS API per tenant.
For more information on rate limiting, please see:
System Dates
Cloud CMS managed dates (such as creation date, modification date, release dates, etc.) are stored as timestamp objects which have the following structure:
{
"timestamp": "01-Jan-1970 00:00:00",
"year": 1970,
"month": 0,
"day_of_month": 1,
"hour": 0,
"minute": 0,
"second": 0,
"millisecond": 1,
"ms": 1,
"iso_8601": "1970-01-01T00:00:00Z"
}
The timestamp field provides a friendly, human-readable value for the time. The components of the time are then broken out by individual fields where all fields are 0-indexed except for the day of the month. The ms field provides the elapsed milliseconds since timestamp or unix epoch counting from 1 January 1970. And the iso_8601 field provides an ISO 8601 formatted value for the time.
Request
Cloud CMS API responses are optimized to be thin by default. The goal is keep the response payload over the wire pretty thin to reduce network latency.
There are a few interesting ways that you can control the response payload using request parameters. A barebones skinny payload response may look like:
{
"_doc": "d0977d2194dfcb8eec61"
}
For single item responses, you will additionally get back any custom properties you have defined. For collections, if you pass in ?full=true, you will get back the full object instead of just an empty shell with the _doc field:
{
"_doc": "d0977d2194dfcb8eec61",
"_type": "my:article",
"_qname": "o:d0977d2194dfcb8eec61",
"title": "Hello World",
"description": "Share and Enjoy"
}
If you pass in ?metadata=true, you will additionally get back system metadata:
{
"_doc": "d0977d2194dfcb8eec61",
"_type": "my:article",
"_qname": "o:d0977d2194dfcb8eec61",
"title": "Hello World",
"description": "Share and Enjoy",
"_system": {
"timestamp": "01-Jan-1970 00:00:00",
"year": 1970,
"month": 0,
"day_of_month": 1,
"hour": 0,
"minute": 0,
"second": 0,
"millisecond": 1,
"ms": 1,
"iso_8601": "1970-01-01T00:00:00Z"
}
}
If you pass in ?paths=true, you will also get back path information:
{
"_doc": "d0977d2194dfcb8eec61",
"_type": "my:article",
"_qname": "o:d0977d2194dfcb8eec61",
"title": "Hello World",
"description": "Share and Enjoy",
"_system": {
"timestamp": "01-Jan-1970 00:00:00",
"year": 1970,
"month": 0,
"day_of_month": 1,
"hour": 0,
"minute": 0,
"second": 0,
"millisecond": 1,
"ms": 1,
"iso_8601": "1970-01-01T00:00:00Z"
},
"_paths": [
"821c40ab613d9b5bcbbc656b62229301": "/My/Folder"
]
}
Cloud CMS allows for multiple mount points and the _paths array will contain the paths for each mount point. The value 821c40ab613d9b5bcbbc656b62229301 is the ID of the repository branch's root folder.
If you pass in ?locale={locale}, you can force the locale of the content served back in the response. This requires that your content have the f:multilingual feature applied to it and that it have some translations. For example, if your content has a translation available for zh_CN (Simplified Chinese), you could add ?locale=zh_CN and get back:
{
"_doc": "d0977d2194dfcb8eec61",
"_type": "my:article",
"_qname": "o:d0977d2194dfcb8eec61",
"title": "你好,世界",
"description": "分享与享受"
}
For more information on internationalization (I18N), see Internationalization.
Pagination
You can use the following request parameters to control pagination of record sets / collections with multiple items:
skip- the index to begin serving content back from within the result set (default is0)limit- the maximum number of items to serve backsort- the sorting to apply to the look-up
For more information, see Pagination.
Response Codes
HTTP status codes are used to indicate the success or failure of the HTTP call. These response codes follow HTTP convention. The most common error codes are:
</tbody>
| Code | Status | Description |
|---|---|---|
| 200 | Success | The request completed successfully and you are being given back the results |
| 301 | Redirect | The requested resource exists somewhere else and the response is being redirected to that location |
| 400 | Bad or malformatted request | The request could not be understood by the Cloud CMS API and so it was rejected |
| 401 | Unauthorized | The request does not have a valid bearer token. Thus, an authenticated user could be established. Cloud CMS does not allow for anonymous access and so the request is being rejected. |
| 403 | Access Denied | The request has a valid bearer token and authenticated user but the user does not have sufficient access rights to access the resource |
| 404 | Resource not found | The request is for a resource that does not exist |
| 405 | Method not allowed | The request specified an HTTP method (for example, POST or PUT) that isn't allowed (for example, when the API call only accepts GET) |
| 429 | Rate Limited Error | The request is from a tenant that has exceeded its maximum number of concurrent connections |
| 500 | Internal Server Error | An error occurred while processing the request |
| 504 | Gateway Timeout | The request took too long to process. This indicates that the request is still executing on the server. It hasn't finished but the API was forced to abandon the call and return early (because the call was taking too long) |
Response Envelopes
The API returns one of three envelopes depending upon the request issued:
- Single item envelope
- Collections envelope
- Error envelope
Single Item Envelope
At a minimum, the returned item will contain the _doc field. This field is the primary ID of the object or datastore being requested. In Cloud CMS, the _doc field is always the primary key field.
{
"_doc": "d0977d2194dfcb8eec61"
}
You may additionally get other properties, depending on what you request. All other properties are entity-specific.
An example:
{
"_doc": "d0977d2194dfcb8eec61",
"_type": "my:article",
"_qname": "o:d0977d2194dfcb8eec61",
"title": "Hello World",
"description": "Share and Enjoy"
}
Collections Envelope
When you run queries, search or traversals or when you pull back children, relatives or perform other lookups into the content graph or into a datastore, you may get back multiple results. These return a result sets (or Collections).
Each result set / collection has a rows array containing the _doc fields for each result. They also have size which provides the total number of rows in the current result set. The total_rows field indicates how many matches there are in total and the offset field indicates the starting cursor location for the returned set.
The size, total_rows and offset fields provide back pagination information about the view of the current set of results being handed back. These work hand-in-hand with the skip, limit and sort pagination options on the request to provide sorting and pagination.
{
"rows": [{
"_doc": "d0977d2194dfcb8eec61"
}, {
"_doc": "d0977d2194dfcb8eec62"
}],
"size": 2,
"total_rows": 4,
"offset": 0
}
If you pass in the request parameter ?full=true, you will get back the full objects (instead of just skinny objects with nothing more than the _doc fields).
{
"rows": [{
"_doc": "d0977d2194dfcb8eec61",
"_type": "my:article",
"_qname": "o:d0977d2194dfcb8eec61",
"title": "Hello World",
"description": "Share and Enjoy"
}, {
"_doc": "d0977d2194dfcb8eec62",
"_type": "my:article",
"_qname": "o:d0977d2194dfcb8eec62",
"title": "Saas that hoopy",
"description": "There's a frood who really knows where his towel is"
}],
"size": 2,
"total_rows": 4,
"offset": 0
}
Error Envelope
If an error occurs on a call, the appropriate HTTP response code will be set and a JSON object will be handed back with additional information about what went wrong.
{
"ok": false,
"error": true,
"message": "You are not permitted to access this resource"
}
Cache Headers
All requests to the Cloud CMS API itself are served back with response headers that are designed to eliminate upstream caching by proxy servers or CDNs.
The headers frequently come back like this:
cache-control: no-cache, no-store, max-age=0, must-revalidate
pragma: no-cache
expires: 0
The reason we do this is the Cloud CMS API itself is dynamic and the resources within the API are ever-changing. It would be far from ideal if a user were to modify a content item in Cloud CMS and then retrieve a cached version where their changes were not present on the next read.
While the Cloud CMS API sets its headers to be fully dynamic, this does not preclude your own applications or your own proxy servers or CDNs from caching. Rather, the onus and discretion of how to do this is handed to the customer and their applications.
Cloud CMS does not impose a one-size fits all caching strategy. Our experience is that every customer is unique so we leave it open to them to cache as they see fit.
If you're looking for a caching middle-tier solution, we recommend taking a look at the Cloud CMS Application Server as it provides caching and CDN-friend cache headers out-of-the-box. It sits between your front-end application and the Cloud CMS API back end and provides an ideal solution for cache management.
HEAD Requests
Cloud CMS supports HTTP HEAD requests to allow you to retrieve pre-flight options regarding the resource being requested. The response from a HEAD request is light in that it doesn't include a response payload. Instead, it is primarily used to retrieve response headers that inform the caller about the resource.
The response headers might look something like this:
accept-ranges: bytes
content-type: application/json;charset=utf-8
content-length: 319
In addition, you will get back CORS headers that might look like something like this:
Access-Control-Allow-Origin: *
Access-Control-Allow-Methods: GET, POST, PUT, DELETE, OPTIONS
Access-Control-Allow-Headers: X-Forwarded-Host, X-Requested-With, Content-Type, Authorization, Origin, X-Requested-With, X-Prototype-Version, Cache-Control, Pragma, X-CSRF-TOKEN, X-XSRF-TOKEN
Access-Control-Allow-Credentials: true
Note that Cloud CMS supports a wildcard on the CORS origin header. If you'd like to constrain this for the purposes of your application needs, we recommend using a middle-tier solution such as the Cloud CMS Application Server.
Range Support
Recent versions of Cloud CMS support the HTTP Range header to allow you to specify the starting byte and ending byte of one or more ranges to retrieve for a given resource. This enables Cloud CMS to be compatible with a broad set of streaming and caching services that require multipart partial content loading to efficiently serve large resource types (such as video and audio files).
Cloud CMS supports the range header across all of its GET API methods for reading resources. This includes API methods that stream back binary attachments as well as API methods that read objects (as JSON payloads).
The accept-ranges response header comes back for every HEAD and GET request and will always have the value of bytes indicating the ranges should be specified using starting and final byte indexes. The content-length header indicates the total length of the content in bytes.
When the range header is used, the response payload will be truncated to the precise range of bytes that you request. It's important to note that, by definition, this means that the response payload may not be structurally complete. The burden is placed on the application developer to use ranges effectively to pull down "chunks" of a response and reassemble them within the application.
Cloud CMS supports single and multiple range specifications.
Here are examples of how the range header can be used:
range: bytes=0-99
range: bytes=0-99,200-299
range: bytes=0-49,100-149,200-249,300-319
The first example (range: bytes=0-99) serves back the first 100 bytes of the resource. Note that the range delimiters are inclusive meaning that the range starts (and includes) byte 0 and ends on (and includes) byte 99.
The second example (range: bytes=0-99,200-299) serves back two ranges. The first range is the first 100 bytes of the resource. The second range is from byte 200 to byte 299.
The third example serves back four different ranges.
When using ranges, the starting range value must always be lower than the ending range value. In addition, a starting and ending value is always required.
If you specify the range header, the response will come back with status code 206 (Partial Content).
It will include a content-range header that indicates the range of the response.
The content-range response headers might look like this:
content-range: bytes 0-99/319
This example might be what comes back for the first range header from above. It indicates that the payload handed back consists of bytes 0 through 99 of 319 total.
If there is error with your range header, you will get back status code 416 (Requested Range Not Satisfiable). You will also get back a content-range header that indicates what is valid.
It might look something like:
content-range: bytes */319
Single Range Requests
When you specify a single range, the response will come back in a non-multiple format.
The status code will be 206 indicating Partial Content.
Each part in the response will have the following headers:
content-typewill be the content type of the resource (such asvideo/mp4orapplication/json)content-rangewill indicate the range of the served content, such as:
Multiple Range Requests
When you specify multiple ranges, the response will come back in a multipart response format where each part is one of the ranges.
The content-type will be multipart/byteranges; boundary=MULTIPART_BYTERANGES where the multipart delimiter is indicated and has the value MULTIPART_BYTERANGES.
The status code will be 206 indicating Partial Content.
Each part in the response will have the following headers:
content-typewill be the content type of the resource (such asvideo/mp4orapplication/json)content-rangewill indicate the range of the served content, such as:
content-range: bytes 0-99/319
This would indicate that this part contains 100 bytes (from index 0 through and including index 99) of the resource. The total size of the resource is 319.
Example using CURL
First, we can make a HEAD call to check whether the Cloud CMS supports the range header for a given JSON resource.
curl -I 'https://api.cloudcms.com/repositories/3b61d917c89cbcd40e5e/branches/1d69237eab15b2d3a3ad/nodes/cbd054cebc179a07ad31'
We get back the headers, including:
accept-ranges: bytes
content-type: application/json;charset=utf-8
content-length: 319
The accept-ranges header verifies that the Cloud CMS API accepts the range header.
Let's now retrieve two ranges from the response using the header range: bytes=0-99,200-299.
curl 'https://api.cloudcms.com/repositories/3b61d917c89cbcd40e5e/branches/1d69237eab15b2d3a3ad/nodes/cbd054cebc179a07ad31' -H 'range: bytes=0-99,200-299' \
And we get back something like
--MULTIPART_BYTERANGES
Content-Type: application/json; charset=utf-8
Content-Range: bytes 0-99/319
{"title":"Test","_type":"n:node","_doc":"cbd054cebc179a07ad31","_qname":"o:cbd054cebc179a07ad31","_
--MULTIPART_BYTERANGES
Content-Type: application/json; charset=utf-8
Content-Range: bytes 200-299/319
":{"a:child":1,"a:child_INCOMING":1,"a:has_role":1,"a:has_role_INCOMING":1},"_is_association":false
--MULTIPART_BYTERANGES--
Additional Range Support
Cloud CMS does not yet support the if-range header. This is on the roadmap, and we are in the process of triaging it.
Getting Started for Developers
In terms of getting started with Cloud CMS and the Cloud CMS API, we recommend visiting our Cloud CMS Developers Page. These pages will guide you through connecting to Cloud CMS for the first time, getting your API Keys and setting up an account if you haven't already.
Cloud CMS API Explorer
The Cloud CMS API Explorer is a Swagger-based user interface that enables you to explore the Cloud CMS API from within your web browser. Using the explorer, you can authenticate and then fire off methods one at a time using the web interface.
The API Explorer is a good way to play around and try things. We also recommend using curl to fire methods by hand. The Cloud CMS SDK provides several curl examples that you can use as a starting point.
The Cloud CMS API Explorer also provides a Swagger compliant JSON file that you can use to potentially generate your own client stub code. Check out the Swagger project for more information.
Cloud CMS Drivers
Cloud CMS also provides drivers for a variety of languages that you can use to interact with the API programmatically. This can save you a lot of time, certainly, and can also inform your own custom development in terms of having working code that you can build upon.