Text Analysis
With Text Analysis in place, a content instance will automatically have its default binary attachment processed through text analysis services to detect and discover meaning contained in the attached text. The text analysis process will detect the following kinds of elements:
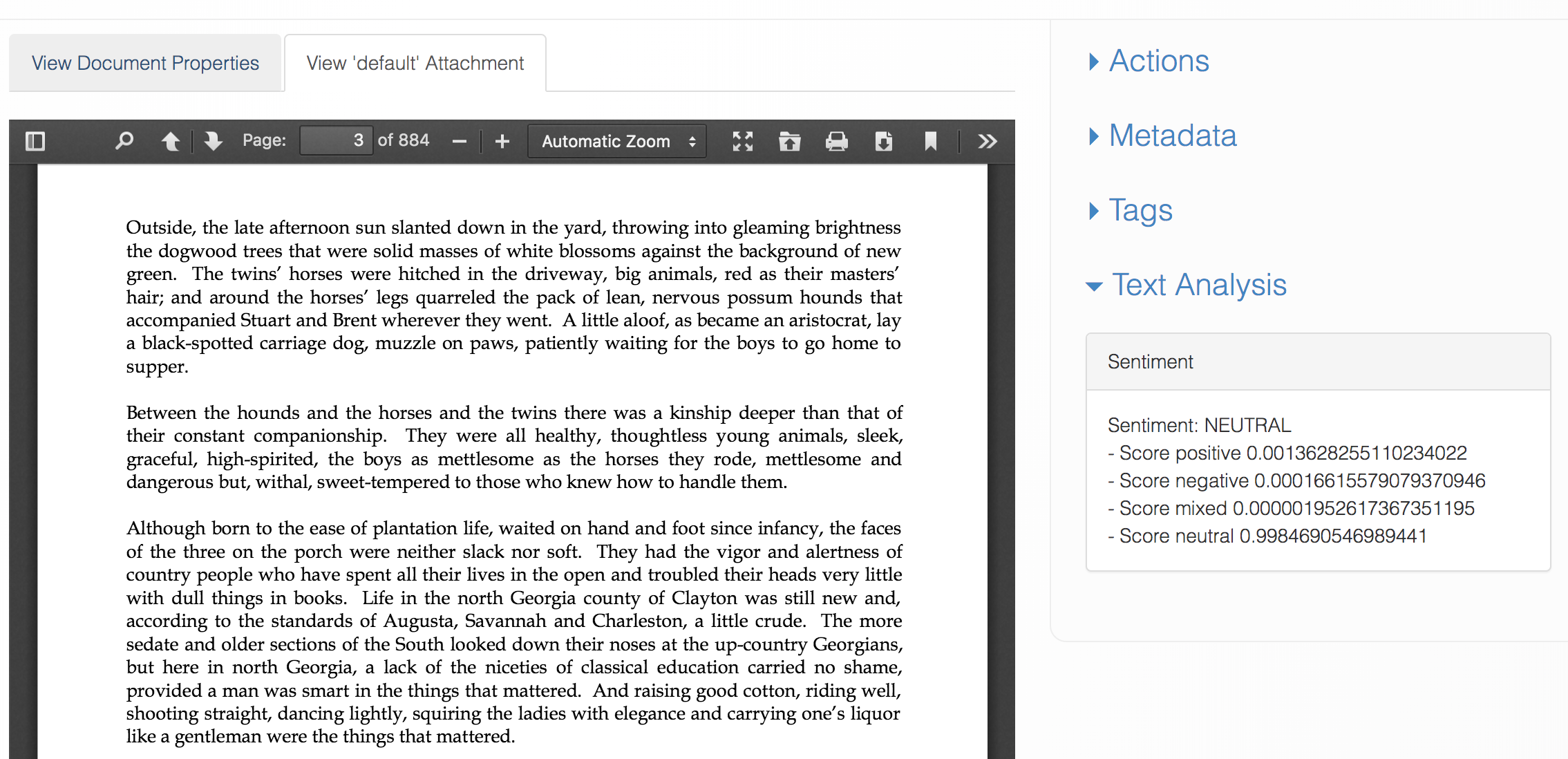
- Sentiment of the text
- Key Phrases contained within the text
- Entities detected within the text
- Languages contained in the text
Any textual content that you place into Cloud CMS will automatically be processed to detect the elements listed above. This allows you to put content into Cloud CMS that includes PDFs, text documents or any content that can be converted into text. Text Analysis will work to automatically determine the sentiment, key phrases, entities and potential languages within the document.
That information gleaned from the analysis will then be populated back onto the Node to help power analysis tools for your editorial team (and to further enhance full-text search).
For example, you might have a PDF attachment of Gone with the Wind - like this:

Using a Text Analysis Service, Cloud CMS will scan the text and detect the sentiment, key phrases, entities and languages of the text. The extracted information will be written back onto the original Node so that your editorial users will be able to work with that information in their daily use.
Triggering Text Analysis
To trigger Text Analysis, you will need to add the f:auto-analyze-text feature to your content instance.
When you add the f:auto-analyze-text feature to a content instance, Text Analysis will run every time you create or update the default attachment of that node. In other words, when you change the binary payload, Text Analysis will automatically run in the background.
For more information on this feature, please check out our formal documentation on the f:auto-analyze-text feature.
Using a Drop Zone
We recommend considering the use of a "Drop Zone" folder to let your editorial users drop images into Cloud CMS whenever they'd like. A Drop Zone folder can be configured to execute a Rule when new content arrives. The rule can then execute the Add a Feature action to add the f:auto-analyze-text feature to newly arrived items.
To do so, you simply set up a Rule on a folder that is bound to the p:afterAssociateNode policy. The Rule runs the Add a Feature action. Now, when a user drops a image (or a PDF or any other content with a binary payload) into that folder, Text Analysis will run.
You might then configure a follow-on action that moves the document to a different folder.
Text Analysis Results
Once Text Analysis has completed, there will be an attachment stored on your node with the results:
text_analysis- a JSON document containing a full breakdown of all recognized elements. This information is very low-level but is useful from a post-processing perspective to glean meaningful insights into the content of the binary payload.
text_analysis
The text_analysis attachment contains raw recognition information about every detected element. Relationships between elements are reflected in the response including positional information on the image.
Here is an example: text_analysis.json
Text Analysis Providers
The following Text Analysis Service Providers are available: