Optical Character Recognition
With Optical Character Recognition (OCR), any binary content that you place into Cloud CMS will automatically be processed to analyze and detect characters, words and meaning. This allows you to put content into Cloud CMS that includes scanned documents with printed or handwritten elements, such as forms filled out by customers or clients or archived documents that your organization seeks to digitize.
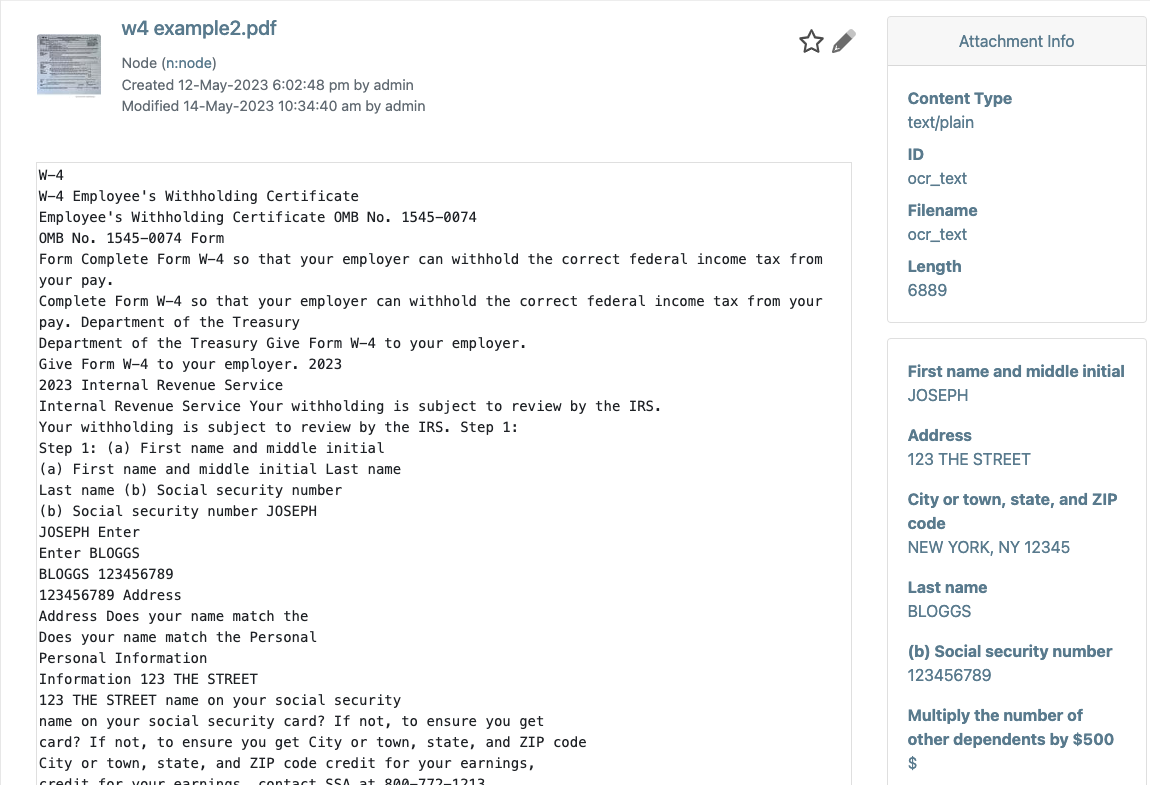
For example, you might have a scanned form that looks like this:

Using an OCR service, Cloud CMS will scan the image, analyze it and detect meaningful information. The extracted, low-level information is made available as well as the extracted text (for full-text indexing) and any detected structured information (such as key/value pairs and table information).
The OCR extraction process will analyze your binary content and detect any meaningful content that is comprised of:
- characters
- words
- sentences
- paragraphs
- pages
- key/value pairs
- table columns, rows and cells
- full text
The extracted content is then stored onto your original Node so that you can work with it from a post-processing perspective. In addition, the Cloud CMS user interface makes use of this extracted content to provide your editorial users with in-context insights and awareness of what was extracted.
Your OCR analyzed content is automatically indexed for full-text search so that your editorial users can quickly find things based on the extracted text.
Triggering OCR Extraction
There are two ways to trigger an OCR Extraction - either by using the f:auto-ocr-extract feature or by setting up a Rule.
Using the f:auto-ocr-extract feature
When you add the f:auto-ocr-extract feature to a content instance, OCR extraction will run every time you create or update the default attachment of that node. In other words, when you change the binary payload, OCR extraction will automatically run in the background.
For more information on this feature, please check out our formal documentation on the f:auto-ocr-extract feature.
Using a Rule (Drop Zones)
You can configure a Rule to conditionally execute the Extract With OCR action whenever a content lifecycle policy trigger. This lets you finely control exactly when an OCR extraction rules.
One thing to consider is a "Drop Zone" folder. A "Drop Zone" is a folder that has a rule on it such that anything that is dropped into that folder will automatically have something done to it. In this case, you might set up a Drop Zone so that any content dropped into the folder has OCR extraction performed on it.
To do so, you simply set up a Rule on a folder that is bound to the p:afterAssociateNode policy. The Rule runs the Extract with OCR action. Now, when a user drops a image (or a PDF or any other content with a binary payload) into that folder, OCR Extraction will run.
You might then configure a follow-on action that moves the document to a different folder.
Extracted Results
Once extraction has completed, there will be 3 attachments added to your node:
ocr_extraction- a JSON document containing a full breakdown of all extracted elements. This information is very low-level but is useful from a post-processing perspective to glean meaningful insights into the content of the binary payload.ocr_text- atext/plaindocument containing all of the extracted text content merged together as a human readable document. This is used to ensure that Cloud CMS will automatically index your OCR extracted content for full-text search and is made available for further use by third parties.ocr_analysis- a JSON document that contains the results of analysis that Cloud CMS performs on the extraction to detect key/value pairs and table row/column/cell information. In effect, this document contains meaningful information that was gleaned from the structure of the results.
ocr_extraction
The ocr_extraction attachment contains raw extraction information about every detected element. Relationships between elements are reflected in the response including positional information on the page. Elements with sub-elements (such as a line containing words) are broken out very distinctly.
Here is an example: ocr_extraction.json
ocr_text
The ocr_text attachment contains a full-text dump of all of the text from the extraction organized sequentially as a reader might expect it to be. The nested structure of related elements is considered when building the full-text representation. It is meant to be human readable and is used internally to ensure that OCR extracted content is indexed within Cloud CMS right away for full-text search.
Here is an example: ocr_text.txt
ocr_analysis
The ocr_analysis attachment contains an analysis that Cloud CMS performs against the ocr_extraction payload. By walking elements and considering their relationships, the analysis reflects discovered content that adheres to a specific structure. This is used to detect Key/Value pairs and Table elements (columns, rows and cell values).
Here is an example: ocr_analysis.json
OCR Providers
The following OCR Service Providers are available: