Deployment
Cloud CMS Deployment lets you publish content from a source Cloud CMS project branch to one or more destination Deployment Endpoints. These Deployment Endpoints may include Amazon S3 buckets, FTP servers, file system locations and Cloud CMS branches on the same cluster or running in a cluster located in another data center somewhere else in the world.
The Deployment process can be triggered manually or automatically. It may run as part of a Publishing process for your content. It may also run as a step within a Workflow model or as a Rule Action triggered when a piece of content's lifecycle state changes.
Typically, Deployment is automated and will work hand-in-hand with Workflow, Rules and Publishing. In the case of Publishing, when the lifecycle state of a piece of content changes (from, say, draft to live), a Workflow is triggered that deploys the content.
The deployment process itself involves marking content items as "dirty". Dirty items are then picked up by a scheduler that routes them in bulk to their destination. Content is transferred "over the wire" as an Archive and Archives are parsed and handled by Deployment Handlers. These handlers then integrate to the respective Deployment Endpoint.
For more information on Archives and their role in Import and Export, please read our documentation regarding the Transfer Service.
Deployment is a bulk transactional process. Multiple content items may be committed to a target receiver at the same time. Receivers may or may not be transactional in their commit of the received bulk content. Most file systems, for example, are -not- transactional in their commit. However, Cloud CMS itself is transactional -- any content written to a Cloud CMS branch commits in its entirety within one transaction. Everything goes or nothing goes.
Cloud CMS provides support for a number of Deployment Endpoints out-of-the-box. These can be set up at any time within the Cloud CMS UI and they will work straight away. These include:
- Project Branches
- File System (Volumes / Disk Mounts)s
- Amazon S3 Buckets
- FTP
- Custom HTTP
- Remote Cloud CMS servers
Cloud CMS Deployment offers a facility that supports a number of common use cases, including:
- The publication of content from an Editorial environment to QA, Staging and Production (Live)
- The mapping and writing of published content to SEO-friendly file or S3 storage (for serving via CDN)
- The replication of content from one Cloud CMS installation to another that supports a live web site
- The movement of content from one data center to another
- The migration of content between projects
The Cloud CMS Deployment process is built to power the content needs of enterprise organizations. As such, it's robust and brings together a number of discrete parts to deliver the overall solution. These parts are described below and together implement a series of patterns that are both highly configurable and extensible.
The components that make up Cloud CMS Deployment include:
- Deployment Handlers
- Deployment Packages
- Deployment Receivers
- Deployment Records
- Deployment Strategies
- Deployment Targets
While Cloud CMS includes a good number of these components pre-built, you are also free to build your own if you have a Cloud CMS on-premise license.
How it Works
For purposes of illustration, lets walk through the following deployment diagram:
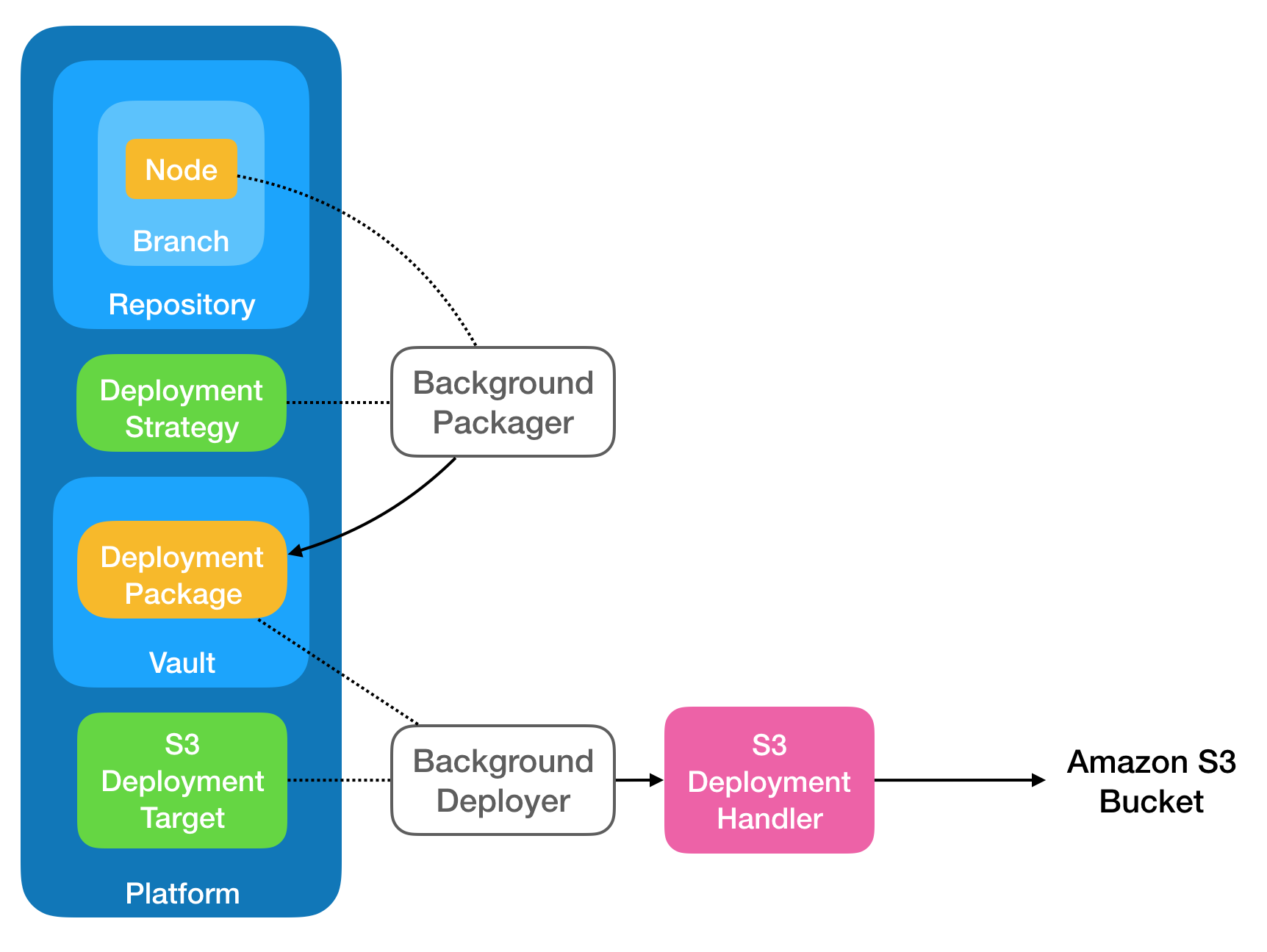
Things begin when a Node (the orange box at the top-left) is changed. Its lifecycle state might be adjust (say, from
drafttolive. This Node is markedDIRTYand things continue as per usual.At some point later, a background packager thread wakes up (somewhere on the cluster) and discovers that the Node was marked
DIRTY. It does this because a Deployment Strategy was defined that provides a recipe about howDIRTYnodes should be discovered and processed. The recipe might indicate that nodes should be packaged upIMMEDIATELYor they might beSCHEDULEDfor periodic deployment.The background packager studies the situation and determines that the node should be packaged up for deployment. It takes the node and creates a Deployment Package from it. A Deployment Package is an object that contains one or more Deployment Records, each representing one of the Nodes being deployed. A Deployment Package also contains an Archive (a binary ZIP) which contains all of the content needed to reproduce the Node in a target environment.
The Deployment Package is written to a deployment Vault. This is done to encourage a nice, scalable separation of concerns. Once the work is done to package up the stuff that needs to be sent (to wherever its going), we can defer the actual (often time-consuming) work of deploying the content until later.
At some other point later, a background deployer thread wakes up (somewhere on the cluster) and looks into the deployment Vault to find any Deployment Packages which are ready to go and which haven't been deployed. It finds our Deployment Package.
The Deployment Package indicates which Deployment Targets are to receive the package. These Deployment Targets come, originally, from the Deployment Strategy (they are copied forward). A single Deployment Package may deploy to one or more Deployment Targets. The Deployment Package is processed against each Deployment Target in turn.
For each Deployment Target, the appropriate Deployment Handler is instantiated and the Deployment Target configuration is passed to the handler.
Each Deployment Handler executes with the provided configuration and Deployment Package. The contents of the Deployment Package are committed by the Deployment Handler and the Deployment Records within the Deployment Package are updated to reflect the commit status (success or failure).
The background deployer thread waits for the deployments to complete. It then reviews the Deployment Package's Deployment Records and reconciles them against the original Nodes. Any Nodes which were marked
DIRTYare adjusted so that they are markedPROCESSEDorFAILED.
In the diagram shown above, the example at hand is one where we're deploying content to Amazon S3. In this case, we take advantage of an S3 Deployment Handler to push content up into an S3 bucket.
Archive Import and Export
As noted above, deployment uses the Transfer Service under the hood to export an deployment package Archive. The Archive contains all of the content that the target might need to perform a holistic import.
The Transfer Service documentation already details many of the nuances involved in assembling the Archive. However, with Deployment, there are a few additional features sprinkled in:
The Archive will additionally contain optional Linked (
a:linked) associations. These associations are not referentially required to satisfy the completeness of the content graph. However, they may be interested at import time since the nodes to which they point may already exist.At import time, the Archive's
a:linkedassociations are considered. If nodes already exist at both ends of the association, then the association is considered in the import's source dependency set. The linked association may be created or it may merged into the target.If either end of the
a:linkedassociation does not exist, it is discarded.
Undeploying
The Cloud CMS Deployment facility also hands undeployment. This is to say that the very same mechanism that is used to describe a set of source dependencies that should merged into a target can also describe a set of source dependencies that should be deleted from a target.
Multiple Deployment Targets
As mentioned, you're free to configure as many Deployment Targets as you wish within your Deployment Strategy or within a Deployment Receiver. Here is an example diagram which is similar to the one we just mentioned. The difference here is that we deploy to both S3 and an FTP server.
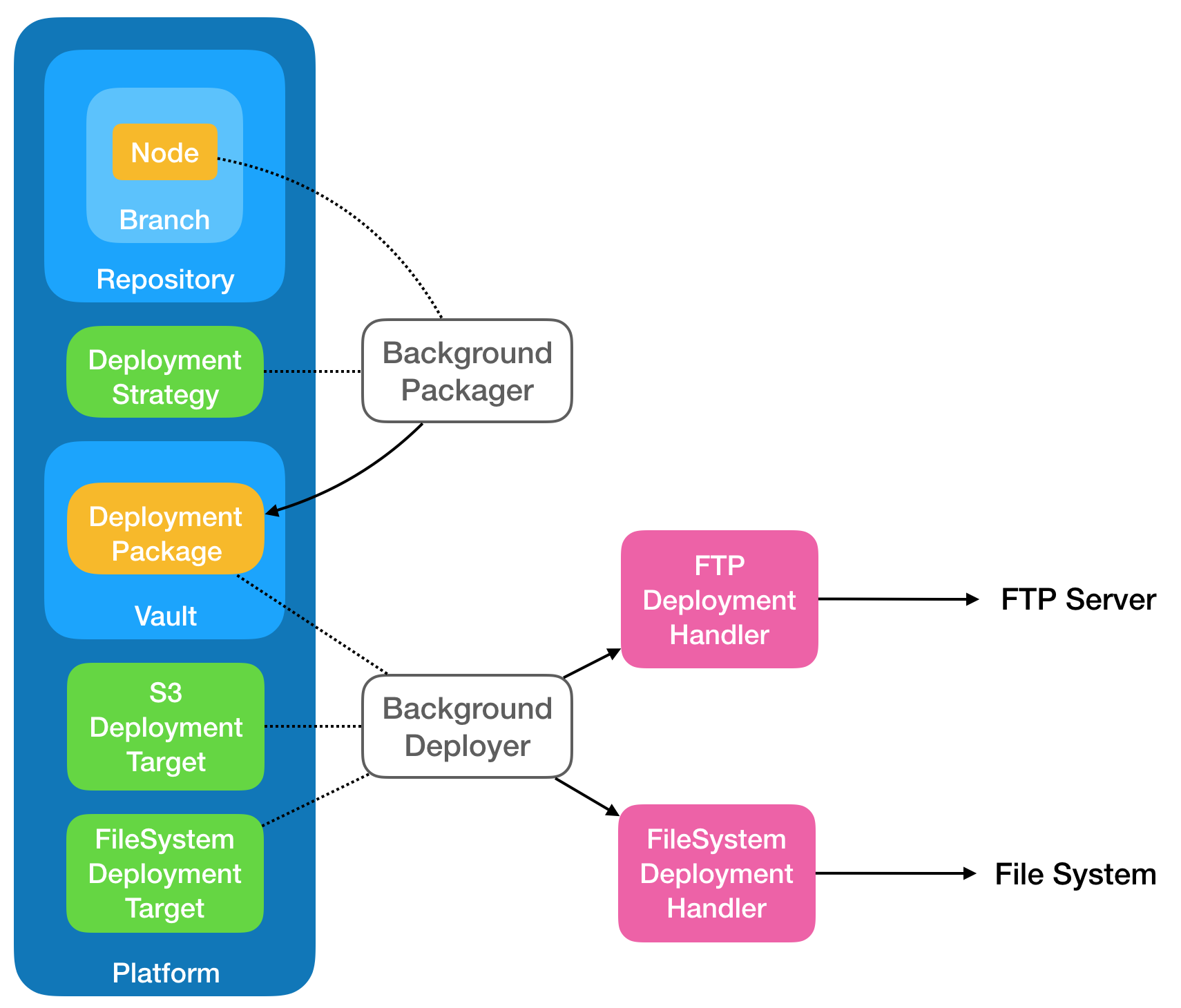
Branch Deployment
Cloud CMS also provides support branch deployment. The Branch Deployment Handler lets you write Deployment Packages to a target branch. Furthermore, the Branch Deployment Handler provides transactional commits to those target branches, ensuring the data integrity of the target.
For branch deployment, the diagram may look a bit like this:
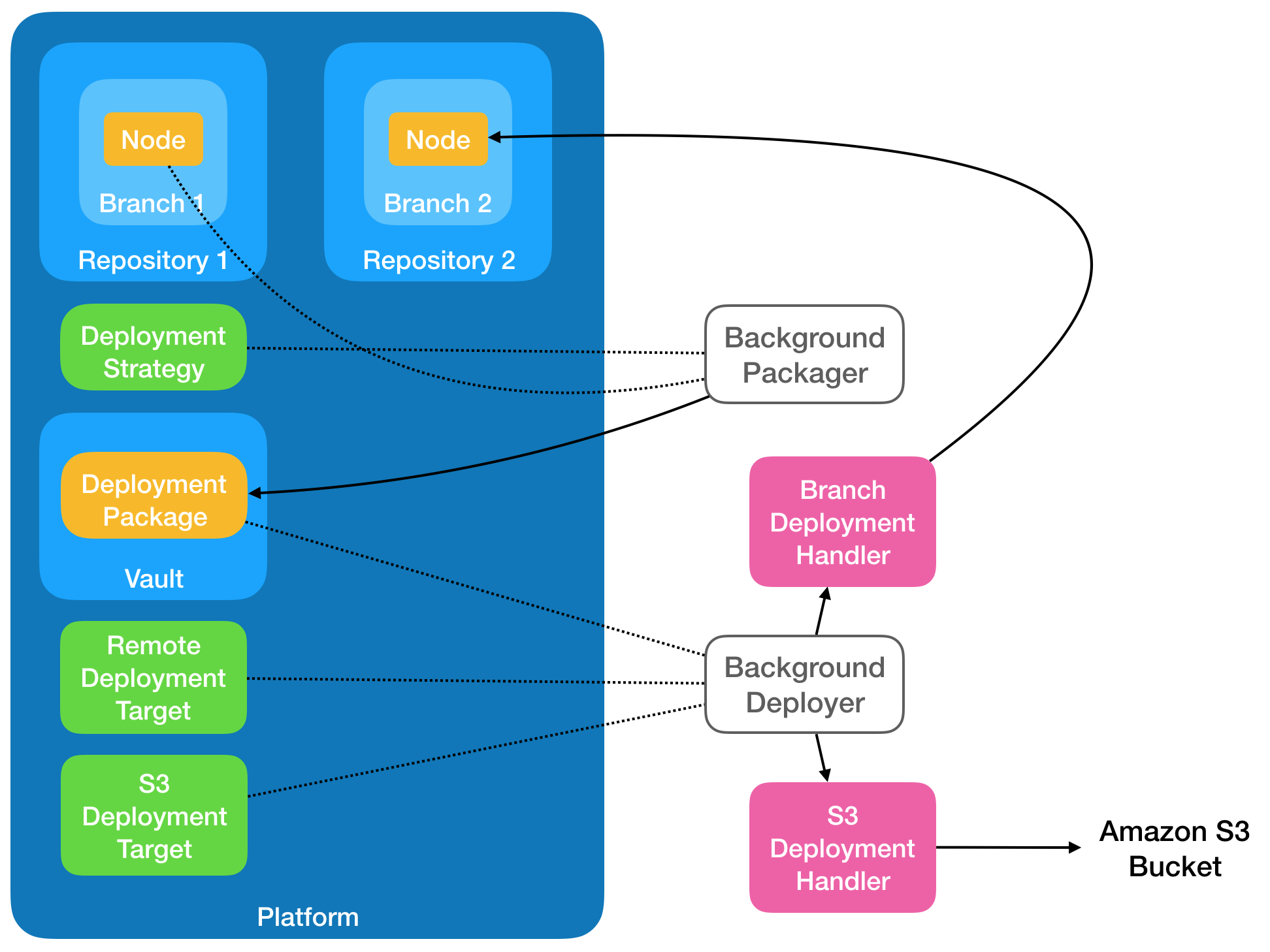
As noted above, deployment uses the Transfer Service under the hood to export Archives and import them into a Deployment Target. In the case of a Branch, this import is performed by the transfer service and the following considerations should be noted:
The import is performed using the
CLONEstrategy. This means that the same IDs will be reflected at the target as they were at the source. This allows for repeated deployment without duplication. It also allows for undeployment using the same IDs as on the source.The
copyOnExistingoption is set tofalse. This means that if collisions are found, they are merged.The
contentIncludeFoldersoption is set totrue. This means that the folder structure of the source dependencies will be maintained on the target.
Deployment Receivers
Cloud CMS also supports the notion of a Deployment Receiver. A Deployment Receiver is an endpoint to which a Deployment Package can be shipped for downstream handling. Once the downstream receiver is finished doing whatever it is going to do with the package, the upstream process continues, using the results to finish things off.
One typical good use of a Deployment Receiver is to support the deployment of content from a source Cloud CMS installation to a target Cloud CMS installation. These two installations may be running in two different data centers in different parts of the world. But content can move between them seamlessly just as if they were moving within a single install.
To support this, a remote Deployment Handler will log in and upload the Deployment Package to a Deployment Receiver running in a different Cloud CMS installation. The remote Deployment Receiver will then do whatever it is configured to do on its end with the content. When its finished, the remote Deployment Handler will learn about what transpired and will reconcile with the original nodes on the source side.