Content Platform
Unlock the value of your enterprise data with a unified content, process and automation platform.
Start working in smart new ways.
Key Features
-
Git-like Branches
Capture every change and idea with limitless changeset versioning. Work in parallel. Fork and merge with visual diffs.
-
Graph Structured Storage
Relational content models for complex, multi-document types with integrated business logic and policies.
-
Enterprise Security
Safeguard, control and audit who accesses valuable digital assets, ensuring robust security and compliance of your content.
-
High performance API
Full-text search, SQL-like query, traversal, GraphQL, path and Vector DB discovery with full version history.
Enterprise Content Management
Cloud CMS lets you manage structured and unstructured content with complex, nested relationships.
Content Nodes are connected together via Associations to form a graph structure that can be traversed, queried or navigated via GraphQL and the API.
-
Data Relationships
Both nodes and associations operate as first-class citizens in our data engine. You are free to model properties and behaviors on top of both, letting you automate business logic as content is worked with and connected within the graph.
-
Relator Properties and Pickers
Design your content types to take advantage of form field types that make it easy for editorial teams to pick and link up relationships in the graph. The data engine keeps these properties in sync going forward, automatically maintaining the graph for you.
-
GraphQL, Traversal, Find
Use GraphQL or our traversal APIs to incorporate the graph into SQL-like query, full-text search and vector embeddings textual search operations. Constrain these find operations around a subsection of the graph.
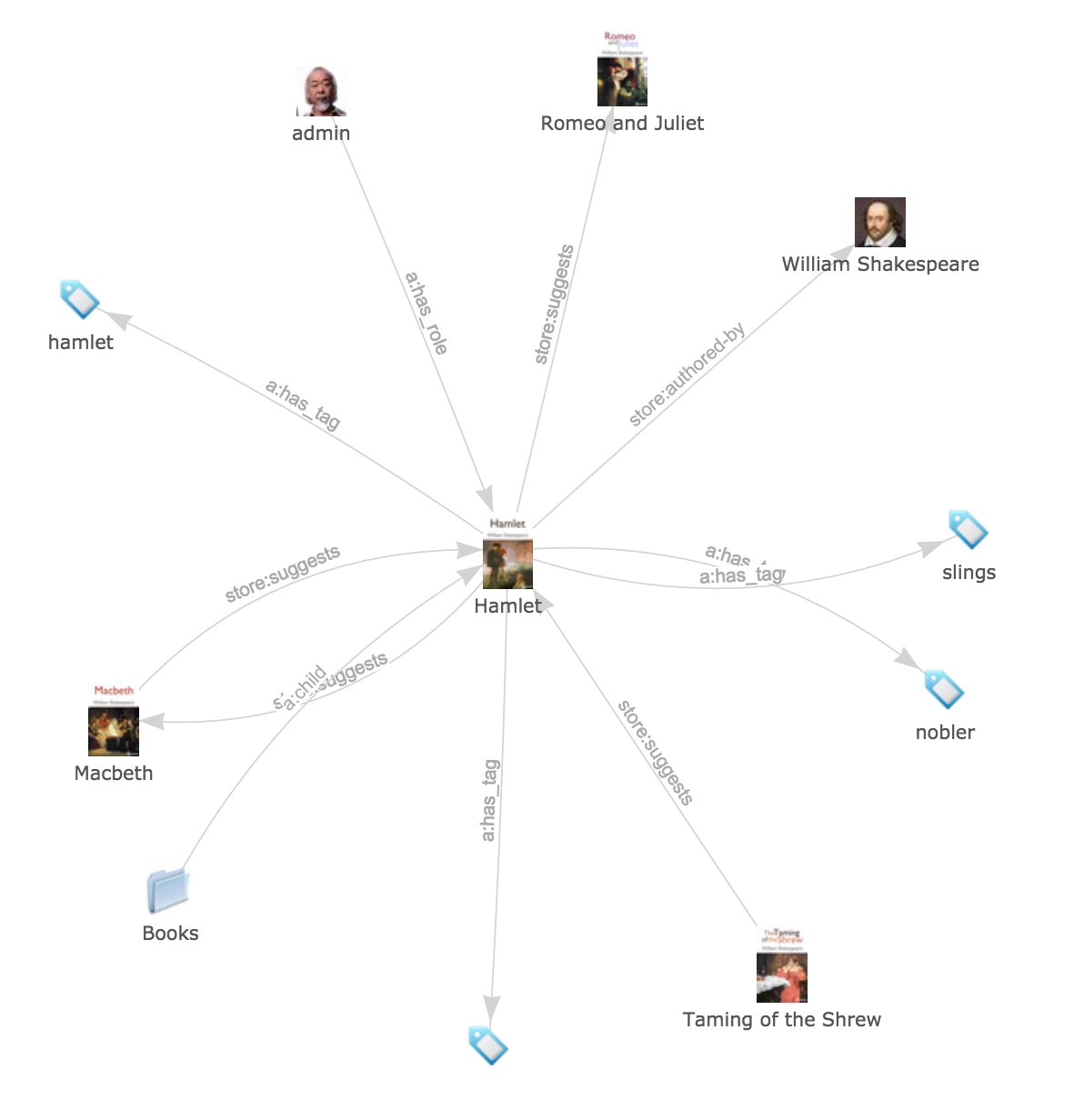
The Content Model
Our content model is graph-based, enabling you to model hierarchical structures and relationships. Nodes and associations are first-class citizens, each maintaining your custom properties and aspect-injected behaviors.
-
Nodes and Associations
Model out custom properties at any depth on top of nodes and associations. Related content together within the graph to build our relationships and meaning.
-
Policy-based Behaviors
Define custom behaviors using rules, server-side scripts or web hooks and bind those behaviors into your content model so they automatically trigger when content is interacted with!
-
Hierarchical and Aspect Oriented
Use inheritance to define parental relationships. And leverage aspect-oriented cross-cutting concerns to inject metadata into your content model tree at any level. Aspects may inject not only properties but also new behaviors!
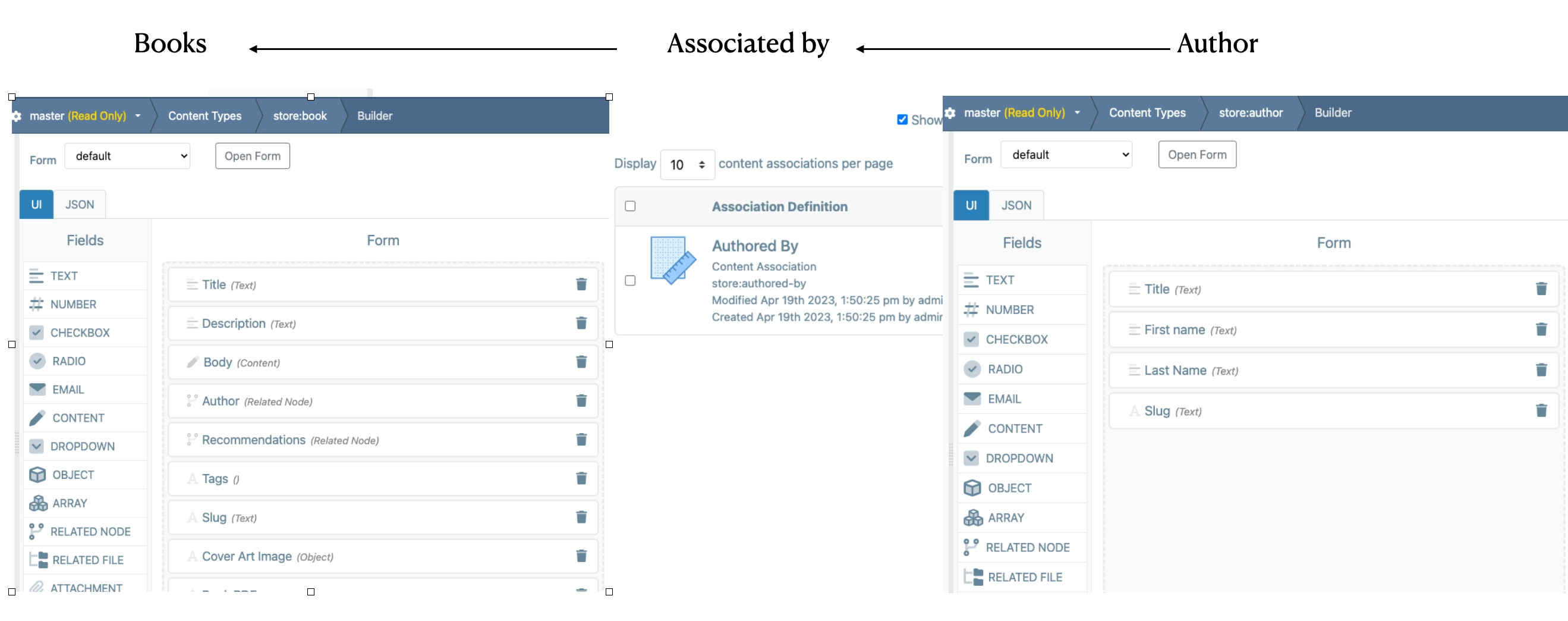
Automatic Rules that run behind the scenes
Connect your custom logic to a vast set of lifecycle policies to handle events in real-time. Fire off web hooks, run server-side scripts or execute custom rules as lifecycle events are raised for your content, branches, pull requests, merges, publications and more.
-
Policies
The data engine supports a very large number of Lifecycle Policies that are raised whenever data state changes. There are typically
beforeandafterhandlers for each policy. Bind your logic into place as a handler to have it trigger and run as folks work on content and changes are introduced. -
Rules, Actions and Scripts
Our rules engine lets you conditionally trigger pre-built actions or custom server-side scripts to sanitize data, perform custom business logic and invoke services precisely as you require.
-
Scripts
The data engine offers a server-side Scripting API that lets you define precise, custom-logic that runs as data lifecycle events are raised. Server-side scripts let you take full control of how your data behaves.
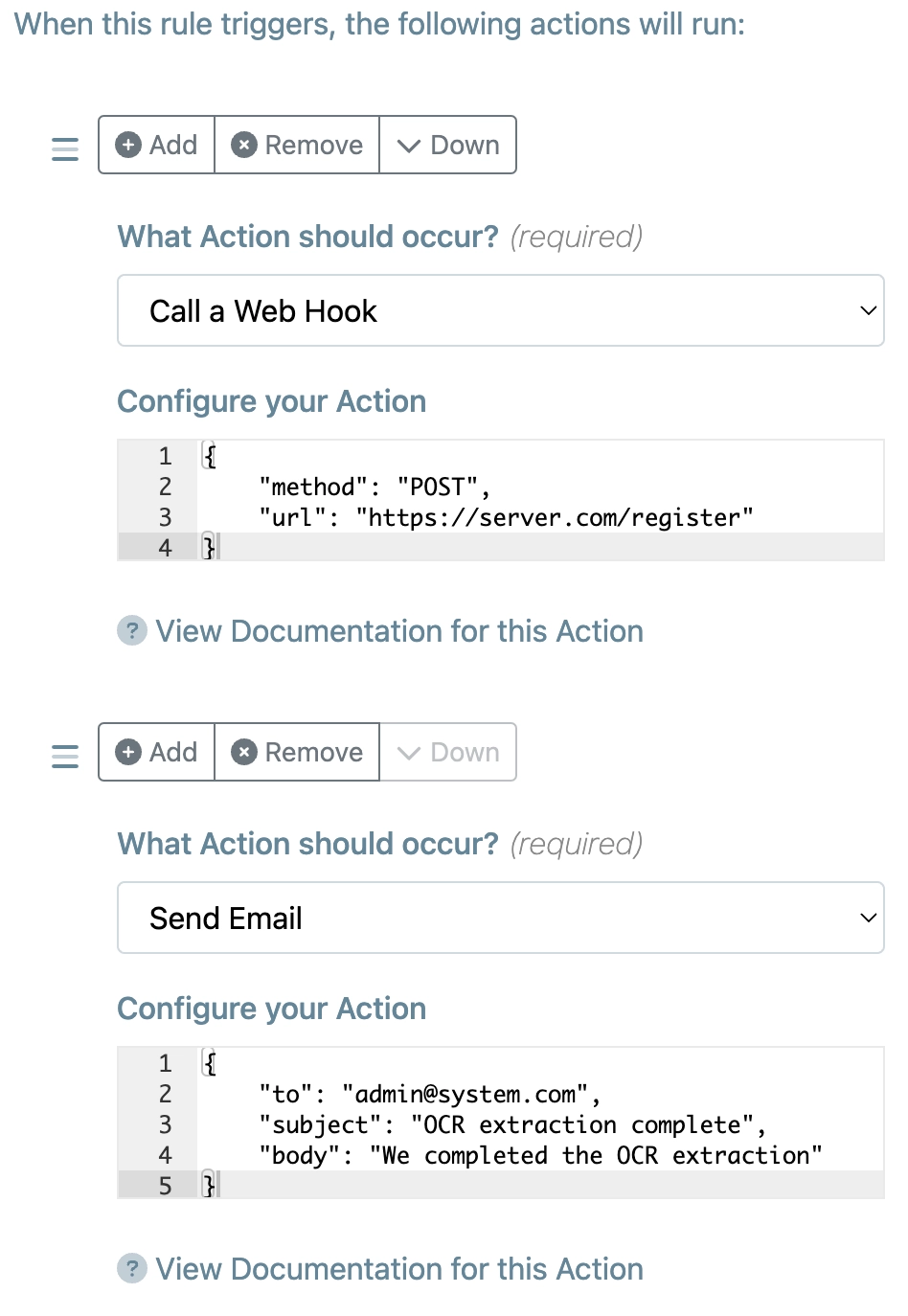
Permissions / Authorities
Secure your data with multiple-layers of robust security, including Access Policies, team-based grants and fine-grained object-level ACL assignments.
-
Access Policies
Centrally manage and assign access policy documents that describe conferred grants and revokes of rights over one or more objects based on conditional statements. Access Policies are enterprise-scoped security governance documents described in JSON format and assigned both globally and per-project to individual users, groups or teams.
-
Teams
Simplify the assignment of access rights by using Teams. Assign a User or a Group of Users to a Team to have them pick up the provisioned access rights. Easily define Editors, Managers, Partners, Suppliers and more.
-
Authorities and Permissions
Group individual Permissions (such as `READ`, `WRITE`, `DELETE`) into Roles (Authorities). Assign Roles to Users, Groups or Teams. Create custom Roles as needed and without limitation.

Peace of Mind with Versioning
The data engine runs atop a changeset versioning system that provides Git-like capabilities for managing commits, branches and merges with automatic and visual conflict resolution. Merge changes, snapshot, tag or rollback/revert commits to restore back to a last-known good state.
-
Full Site Versioning
Capture every change. Every create, update or delete to every content item is stored on a transactional commit. Never lose data and rest easy with a Peace of Mind assurance that you always preserve the ability to roll back to a last known good state.
-
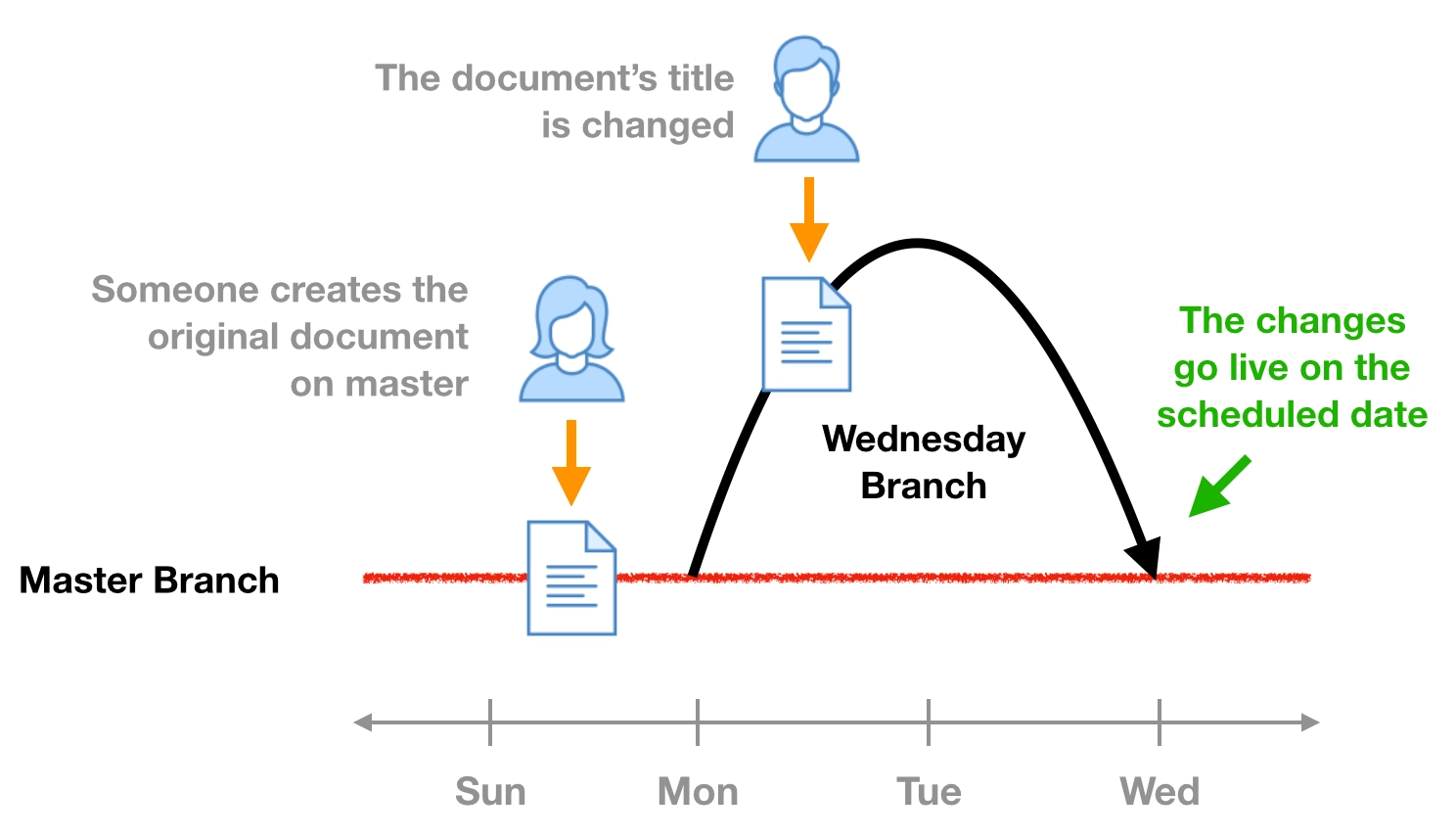
The Freedom to Contribute
It's easy for editorial users to create new branches and try out new ideas. Write fresh and inspired updates to your web content. Cherry pick from the best ideas to pull together your final, approved and published release.
-
Tag, Snapshot and Aliases
Use Tags, Aliases and Snapshots to mark your branches with labels that are used to dynamically switch the live or active branch powering your web site. Or set up deployment rules that automatically deploy content from an approved branch to a live branch on a different project or running in a different data center altogether.
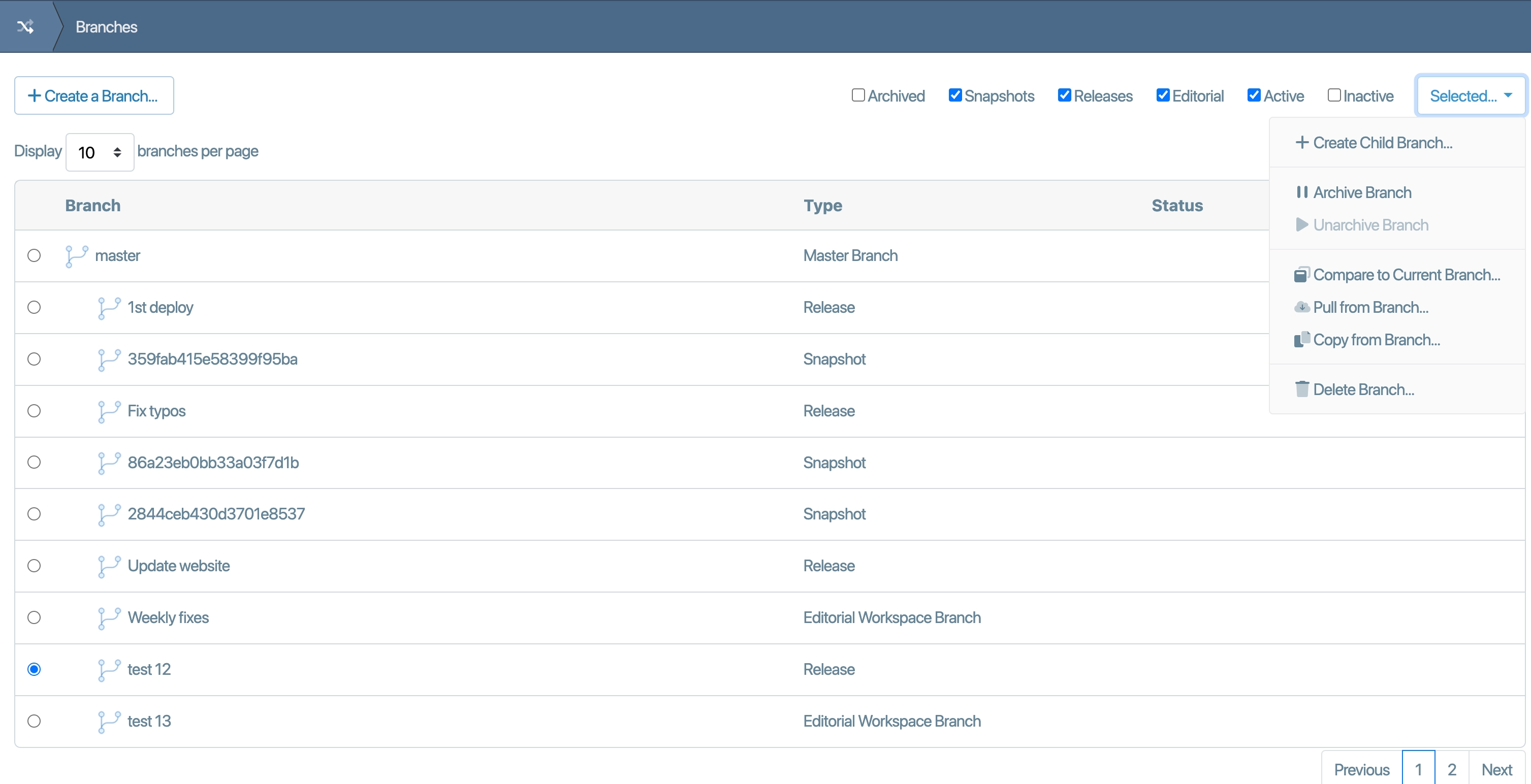
Capture every edit, preserve every Change
Utilize branches to create draft and development workspaces where content can be curated, honed and tested before being merged upon approval. Merge conflicts are automatically detected and visual tools let you perform side-by-side differencing and conflict resolution.
-
Safe and Isolated Editing
Work on new content, fix typos, correct mistakes, or safely experiment with new ideas in a private, contained and isolated editorial area that belongs just to you.
-
Avoid Stepping on Each Other's Toes
With branches, everyone can work in parallel. That way, everyone is free to get things done and then bring their work together at the end. Merge using Pull Requests or directly. Side-by-side visual tools make it easy to compare changes and cherry pick the best ideas.
-
Keep the Best Contributions
Visual Comparison and Differencing between branches lets you find changes and Merge them into your own branch. Cherry Pick the best ideas and use Side-by-Side visual differencing tools to work out any Merge Conflicts as they arise.
Authentication
Authentication ensures that only authorized users have access to this information, which helps to prevent unauthorized access and protect against cyberattacks. Many industries and regulatory bodies require authentication to be implemented in content management systems to comply with data protection regulations and privacy laws.
-
Secure login to your tenant
Gitana requires an authenticated Client and authenticated User for all API interactions. As such, Gitana does not support the Client Credentials Grant and it also does not support Implicit Grant.
-
Single Sign On (SSO)
Single Sign On (SSO) Enterprise support that provides ways for users to log in using their existing business accounts. It makes it possible for your users to authenticate to Gitana without having to remember or type in their credentials every time.
-
Multifactor Authentication (MFA)
With Multifactor Authentication enabled for a user, that user will be required to supply a verification code in addition to their username and password. The verification code is delivered to the user's phone or mobile device via SMS, a phone call or an app. The code may also be delivered via a hardware device depending on the kind of provider you configure.

Distributed Job Queue
The Distributed Job Queue is a system that allows tasks to be distributed and managed across multiple servers or nodes in a Gitana environment. This is necessary for managing tasks that are resource-intensive, time-consuming, or require coordination across multiple nodes.
-
Dedicated Job Queue
Some jobs may be large and could have a negative impact on other jobs by causing jobs to be queued up waiting. For example, a large Bulk Import, or, you may require your Users not be impacted by system jobs. Dedicated queues can be used to allocate jobs to particular queues.
-
Priority Jobs
Not all jobs are equal to a business. For example, publish of Live content has a higher priority compared to publishing of Draft content.
-
Additional Job queues
With increased use it may be necessary to scale with additional Job Queues. Gitana has the option of scaling with additional queues.
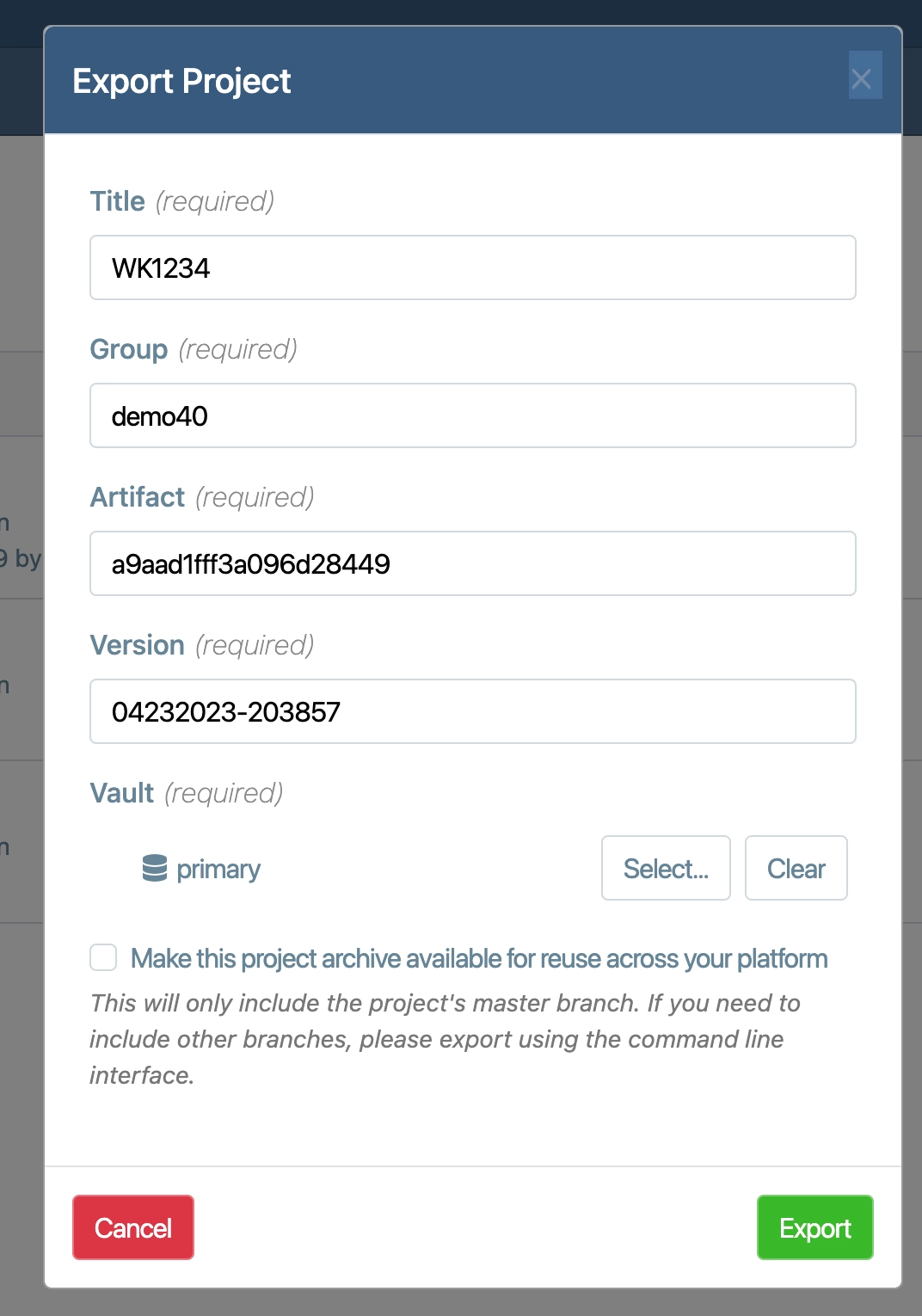
Transfer Services
The API-driven transfer layer makes it very easy to transactionally import and export all of your content including the content graph, binary files, users, application data and everything else!
-
Backup
Your data is exported into a ZIP-based archive. Archives are stored and moved between Vaults to migrate data between tenants. Or download archives for local storage and redundancy.
-
Restore
Restore your projects, content, branches and more from an exported archive into any environment. Punch out copies of your data into local, test and user acceptance environments or replicate data into production with ease.
-
Bulk Loading
Our Packager library makes it easy to pull in data from external data sources including file systems, databases, CSV files and more. Package this data into archives that are built offline and the bulk import everything in one single, transactional operation.
Easy to connect
Fully-powered REST API, GraphQL and a large set of prebuilt drivers make it easy to connect to Gitana and work with your content.
-
Secure
Powerful, high performance API for all of your content creation and retrieval needs Authentication is performed using OAuth 2.0 and features encrypted bearer tokens that are compatible with your Enterprise Single Sign On strategy.
-
Powerful
Every function and capability of Gitana is available via the API, no matter whether for editorial or delivery purposes. Take advantage of pagination, sorting and response payload size filtering universally across all methods and GraphQL.
-
Formats and Drivers
Full support for JSON, XML, YAML and binary formats (Smile, CBOR, Avro and MessagePack among others) with request and response payloads. We also offer drivers for most popular languages and frameworks including Node, JavaScript, C#, Go and Java!

Ready to Get Started?
Unlock your data with smart content services and real-time deployment