Clustering
The Cloud CMS Application Server supports running on a single Node process as well as multiple Node processes. Node processes can run on a single server instance or can be spread across multiple server instances behind a load balancer.
By default, the Application Server starts up and allocates itself to a single CPU. This is known as single mode. Even if you have a server with more than one CPU on it, the Application Server will still only bind to 1 of those CPUs.
When the Application Server is bound to a single CPU, any server-side state that it is required to manage can be done so in memory. However, if the Application Server spreads out across multiple processes, any server-side state will be stored in a shared backend. The Application Server provides out-of-the-box support for Redis to achieve this.
Modes
To set the setup mode, you should provide the following configuration:
{
"setup": {mode}
}
Where mode can be any of the following:
singleclustersticky-cluster
For example:
{
"setup": "cluster"
}
You can also set the mode by using the CLOUDCMS_LAUNCHPAD_SETUP environment variable. For example:
CLOUDCMS_LAUNCHPAD_SETUP=cluster
The three different modes of operation describe how Node worker processes are allocated to CPUs on a single server and further describe routing strategies for requests to the worker processes (round-robin vs sticky).
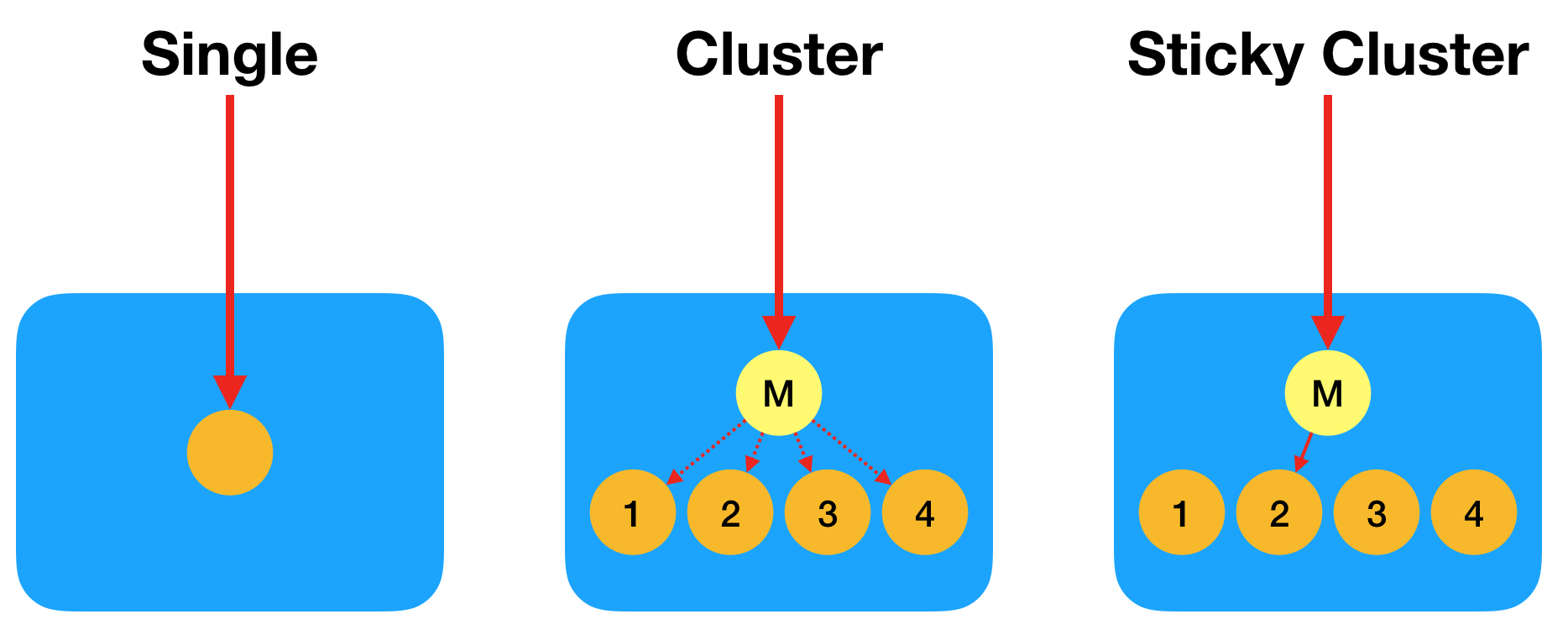
Single Mode
The single setup mode is the default mode. It allocates a single Node process to a single CPU (regardless of the number of CPUs on your server). When running in this mode, any services that manage server-side state will configure to use in-memory providers.
Cluster Mode
When running in cluster setup mode, the Application Server will allocate multiple Node processes - one for each CPU on your server. If you server has 4 CPUs, you will have 4 Node processes running. To achieve this, the Application Server uses the Node Cluster facility to spawn N number of worker processes and a single master process.
When requests arrive to the master process, those requests are forwarded to a worker process using a round-robin approach. This spreads requests evenly across your processes, allowing you to utilize of each of the CPUs on your server.
When running in this mode, any services that manage server-side state will configure by default to use Redis as a storage provider. Redis acts as a transient database, a cache and a message broker for the live Node processes so that they share data across the cluster.
It's important to note that Redis (or a similar external storage provider) is required even in the case where you have multiple CPUs on a single server. If you run in cluster setup mode, even on a single server, you essentially will have N number of isolated processes (for N CPUs on the servers). For all intents and purposes, you can think of these isolated processes and separate servers. They are unaware of each other. A shared backend storage provider is therefore needed to storage shared state.
Sticky Cluster Mode
As noted above, when running in cluster mode, a straight-forward round-robin approach is used to route requests from the master process to the worker processes. As such, it is possible for a browser to make multiple requests and have those requests be services by different CPUs (or different worker processes).
You can change this behavior so that subsequent requests arrive to the same worker process by using sticky-cluster mode. If sticky-cluster is configured, then a browser making multiple requests will have all of their requests serviced by the same CPU (and the same worker process).
You will need to use sticky-cluster if you're using any services that leverage Web Sockets. This is due to the way that Web Sockets work. With Web Sockets, a "socket" is being held open between the client and the server. Even with virtualized abstractions (such as HTTP long polling), the server-side requires that client to consistently connect to the same backend process on repeated connections.
For example, if you are using the Awareness Service (which supports Web Sockets for real-time, client-side messaging), then you will need to use sticky-cluster.
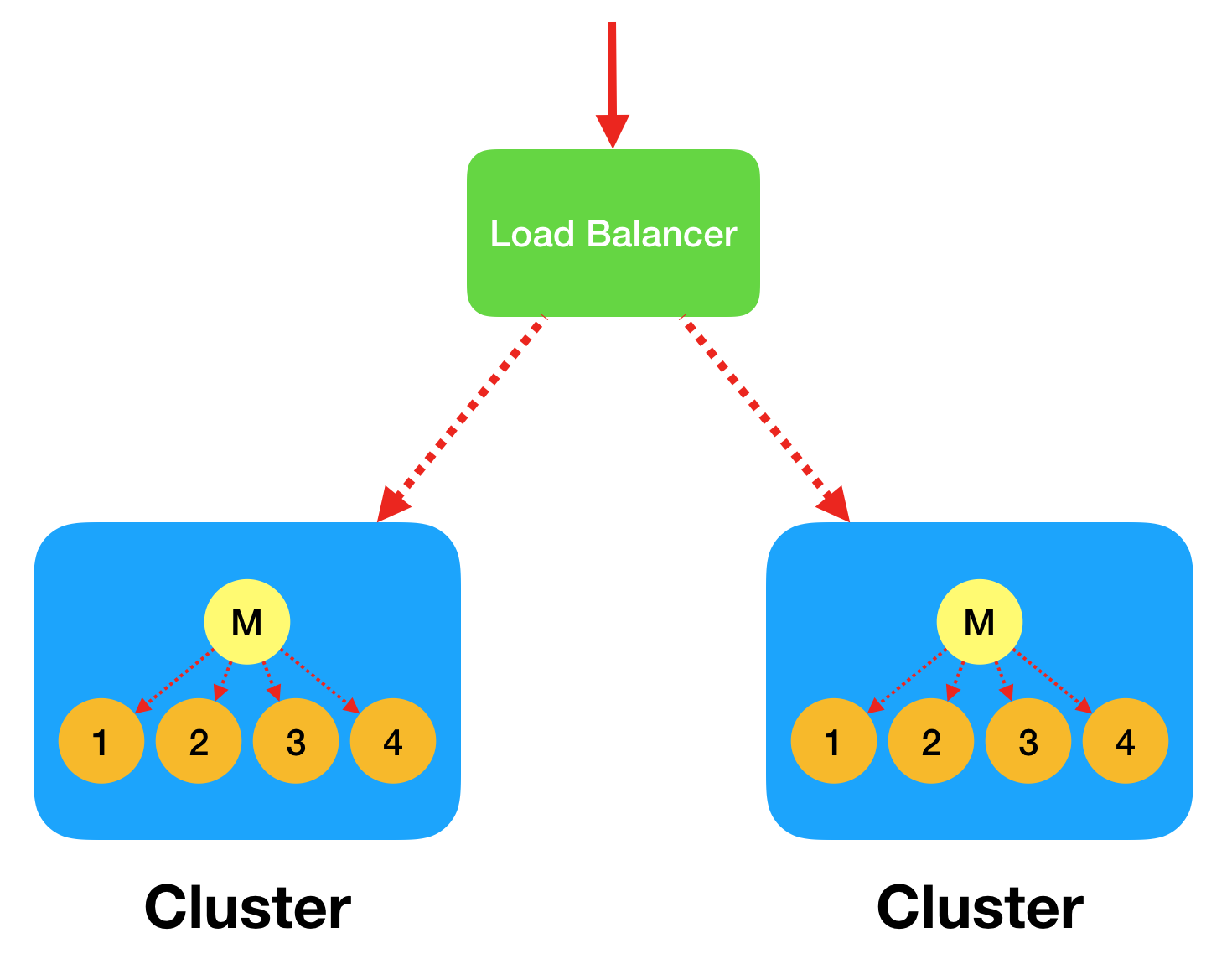
Multiple Servers with a Load Balancer
When you're running multiple servers, you will need to provision a load balancer ahead of them so that incoming requests distribute across the servers. On each individual server, you can then set the mode (as per the instructions above) to then determine how those requests will route from the master process to worker processes.
When running in cluster mode, it is assumed that any single request can route to any server and to any worker process on the chosen server. You will want to configure your load balancer to use a round-robin or similar strategy so that any single request can end up on any server and any process. This balances the cluster.
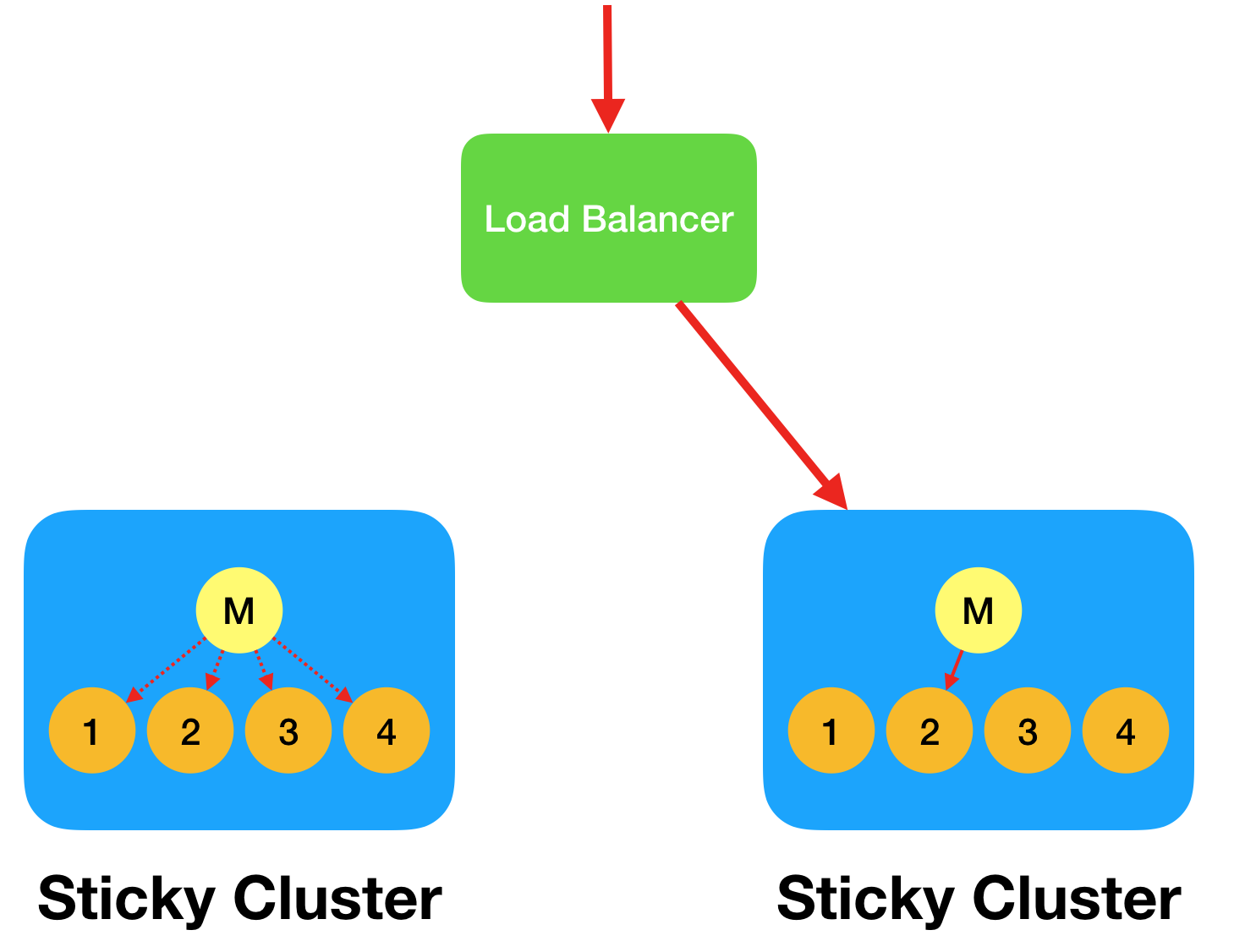
When running in sticky-cluster mode, you will want to set up the load balancer so that repeated requests from the same client route through to the same server. Once the request arrives at the destination server, the Node master process will use a sticky algorithm to route the request to the same worker process. As noted, this is required to support Web Sockets.
Configuring Redis
The following services require a Redis configuration when running in cluster or sticky-cluster mode.
You can either configure these services one-at-a-time or you can provide Redis configuration via environment variables.
The following environment variables can be used to globally configure Redis for all dependent services:
CLOUDCMS_REDIS_DEBUG_LEVEL- eitherinfo,warn,errorordebugCLOUDCMS_REDIS_ENDPOINT- thehostCLOUDCMS_REDIS_PORT- theport
If these environment variables are set, they will be applied automatically to the services listed above.